
Posts tagged Hazelcast
Payara Server's High Availability Architecture: A Quick Technical Overview
Published on 05 Jun 2024
by Luqman Saeed
Topics:
JMS,
Hazelcast,
Payara Server,
Payara Platform,
Payara Enterprise,
Payara Community,
Jakarta EE
|
2 Comments

Introduction
In today's business world, competition is fierce and relentless. As a result, maximizing uptime while reducing downtime and its expenses is a top priority. In particular, users now expect applications to deliver consistent performance, regardless of unexpected challenges. Payara Server offers a high availability (HA) architecture that is designed to keep your business operational at all times. This blog post explores the components and configurations needed to create a highly available Payara Server environment, ensuring your applications remain accessible and responsive.
Remote CDI Events in Payara Platform
Published on 26 Dec 2022
by Luqman Saeed
Topics:
Hazelcast,
CDI,
JakartaEE,
Jakarta EE
|
0 Comments

The Jakarta Contexts and Dependency Injection API is the standard dependency injection framework on the Jakarta EE Platform. The latest version of the CDI specification that shipped withJakarta EE 10 is CDI 4.0. This release features a split of the core CDI API into Lite and Full. CDI Lite is designed to run in more restricted environments, and features a subset of the original features. CDI Full contains the Lite and all other features that were in core CDI in previous Jakarta EE releases.
Using Hazelcast SQL with Payara Micro
Published on 27 Sep 2021
by Rudy De Busscher
Topics:
Payara Micro,
Hazelcast,
Clustering,
domain data grid
|
0 Comments

Co Authored with Nicolas Frankel (Hazelcast Developer Advocate), this article is also available as a PDF.
The Hazelcast In-Memory Data Grid (IMDG) is an efficient method of storing data in a distributed way within the memory of the different processes of the cluster. Because it is distributed, searching the data locally requires 'moving' the data to your instance so it can be accessed, which is not overly efficient. Hazelcast SQL allows distributed queries which perform the search where the data is, and then transfers only the results to your process. Since the Payara products already use Hazelcast IMDG, using the Hazelcast SQL capabilities is straightforward: just add the additional JAR library to start using it.
How to Connect Payara to External Hazelcast Grid
Published on 25 Mar 2021
by Rudy De Busscher
Topics:
Production Features,
Hazelcast,
Payara Platform 5
|
2 Comments

The Domain Data Grid feature of the Payara products is powered by the Hazelcast library. It provides the necessary functionality for the Deployment Group (clustering functionality), Cache functionality, CDI cluster singleton, and monitoring data storage within Payara to name just a few features.
Since Hazelcast can cluster multiple instances into a data grid, it is possible to create a Hazelcast grid that comprises the Payara instances and some other instances included in other applications running outside of Payara.
Did You Know? Payara Platform Can Cluster By DNS
Published on 17 Dec 2018
by Jonathan Coustick
Topics:
Hazelcast,
Clustering,
Payara Platform
|
2 Comments

Hazelcast in the Payara Platform offers several ways to configure how instances cluster. One new way is by using DNS records.
Creating a Simple Deployment Group
Published on 24 Aug 2018
by Matthew Gill
Topics:
Hazelcast,
Clustering,
Payara Server Basics - Series,
Payara Server 5 Basics
|
5 Comments

Note: This blog post is an update to Creating a Simple Cluster, which was written for Payara Server 4.
Introduction
Continuing our introductory blog series, this blog will demonstrate how to set up a simple Hazelcast deployment group containing two instances. Deployment groups were introduced with Payara 5 to replace clusters. They provide a looser way of managing servers, allowing instances to cluster by sharing the same configuration whilst providing a single deployment target for all of them. See here to read more about Deployment Groups.
Setting Up Cache JPA Coordination with the Payara Platform using EclipseLink and JMS/Hazelcast
Published on 21 Jun 2018
by Lenny Primak
Topics:
JMS,
Hazelcast,
Clustering,
Eclipse
|
6 Comments

When it comes to clustering and distributed computing performance, some of the challenges you have to overcome involve cache invalidation and coordination. Fortunately, both Payara Server and Payara Micro come with EclipseLink, which supports cache coordination and invalidation out of the box. This blog will explain how to configure this feature for your Payara Data Grid. We would also like to thank Sven Diedrichsen who is the community member that created the Hazelcast cache coordination.
Fundamentos de Payara Server Parte 6 - Creando un cluster dinámico con conmutación por fallas en Payara Server con Hazelcast
Published on 29 May 2018
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
1 Comment
Avanzando más nuestra serie de blogs de introducción, esta entrada mostrará como puedes escalar de forma dinámica tu cluster, y como Payara Server maneja la conmutación por fallas entre miembros del cluster.
See here for the original version in English language.
La conmutación por fallas es la habilidad de continuar proporcionando acceso a nuestro sitio web o aplicación en el caso de que un servidor falle. Es una parte importante de un servicio que goza de alta disponibilidad, cuyo objetivo es minimizar los tiempos de inactividad a lo largo de tu infraestructura de servicios.
Domain Data Grid in Payara Server 5
Published on 23 Jan 2018
by Steve Millidge
Topics:
Microservices,
Hazelcast,
Clustering,
Scalability,
Cloud,
Amazon Cloud,
Cloud Connectors,
Payara Server 5,
Cloud-native,
domain data grid
|
0 Comments
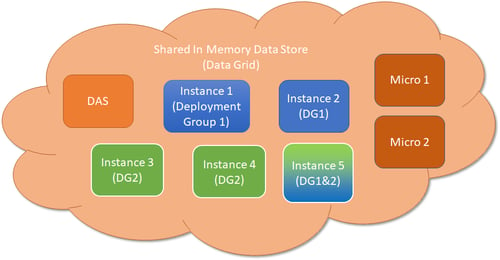
In Payara Server 5 we will be introducing some major changes to the way clustering is working by creating the Domain Data Grid (see documentation for more info). The Domain Data Grid will be easier to use, more scalable, more flexible and ideally suited for cloud environments and cloud-native architectures. All Payara Server instances will join a single domain-wide data grid for sharing of in-memory data like web sessions, JCache, SSO and Stateful EJBs.

Kubernetes Native Discovery with Payara Micro
Published on 20 Dec 2017
by Susan Rai
Topics:
Payara Micro,
Microservices,
Hazelcast,
Clustering,
Cloud,
Kubernetes
|
1 Comment

Payara Micro supports Hazelcast out of the box, and can be used for clustering. This allows members in the cluster to distribute data between themselves, amongst other things. By default, Hazelcast comes with multiple ways to discover other members in the same network. A multicast discovery strategy is commonly used for this purpose; a multicast request is sent to all members in a network and the members respond with their IP addresses. Another strategy must be employed if a member cannot or does not wish to provide their IP address.