
Posts tagged Amazon Cloud
Thinking About Migrating to Hybrid Cloud?
Published on 13 Aug 2019
by Susan Rai
Topics:
Cloud,
Amazon Cloud,
Hybrid Cloud
|
1 Comment

This blog aims to give you a short overview of Hybrid Cloud, its benefits and limitations, how to tackle these limitations and finally - why the Payara Platform is the right choice if you are thinking about migrating your business to Hybrid Cloud.
Taking Payara To The Cloud
Published on 29 Mar 2018
by Mike Croft
Topics:
Payara Micro,
Cloud,
Amazon Cloud,
Cloud-native,
Payara Server
|
0 Comments

It may be hard to believe in 2018, but there was once a time before Amazon Web Services. In 2006, Amazon launched what was to become the most dominant platform in cloud computing - the Elastic Compute Cloud (EC2). While there were a lot of early adopters who could see the benefits of "Infrastructure as a Service" (IaaS) style cloud computing - a notable example being Dropbox - there were many who were sceptical of the hype around the "cloud" and prompted stickers like the one pictured.
Domain Data Grid in Payara Server 5
Published on 23 Jan 2018
by Steve Millidge
Topics:
Microservices,
Hazelcast,
Clustering,
Scalability,
Cloud,
Amazon Cloud,
Cloud Connectors,
Payara Server 5,
Cloud-native,
domain data grid
|
0 Comments
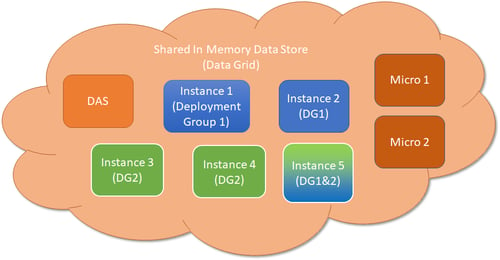
In Payara Server 5 we will be introducing some major changes to the way clustering is working by creating the Domain Data Grid (see documentation for more info). The Domain Data Grid will be easier to use, more scalable, more flexible and ideally suited for cloud environments and cloud-native architectures. All Payara Server instances will join a single domain-wide data grid for sharing of in-memory data like web sessions, JCache, SSO and Stateful EJBs.

AWS Native Discovery with Payara Micro
Published on 23 Nov 2017
by Mike Croft
Topics:
Java EE,
Payara Micro,
Microservices,
Hazelcast,
Caching,
Cloud,
Amazon Cloud,
Uber JAR,
Cloud-native
|
1 Comment

Both Payara Server and Payara Micro can cluster together and share data using Hazelcast. Out-of-the-box, there is no configuration needed, since Hazelcast uses multicast to discover and join other cluster members. However, when running in cloud environments like AWS, for example, there are a lot of things which can stop discovery being quite so straightforward. The key thing is that Multicast is not available, meaning another discovery strategy is needed; the most common generic alternative is to use TCP, but this assumes that you know at least the intended subnet that your cluster members will be in ahead of time.
Payara Micro JCA Adapters - Amazon SQS
Published on 26 Jul 2017
by Matthew Gill
Topics:
What's New,
Payara Micro,
Microservices,
Cloud,
Amazon Cloud,
Cloud Connectors
|
3 Comments

In this blog, which follows on from the Cloud Connectors in Payara Micro, we will explain the Amazon Simple Queue Service (SQS) connector and how to use it in Payara Server / Micro.
Cloud Native Java EE
Published on 29 Sep 2016
by Dominika Tasarz
Topics:
Java EE,
Payara Micro,
Microservices,
Docker,
Cloud,
Amazon Cloud,
MicroProfile
|
0 Comments

The video tutorial by the Payara Support Engineers Mike Croft and Ondrej Mihalyi, presented at the JavaOne 2016 Conference in San Francisco last week is now available to watch online!