
Originally published on 23 Jan 2018
Last updated on 07 Jul 2021

In Payara Server 5 we will be introducing some major changes to the way clustering is working by creating the Domain Data Grid (see documentation for more info). The Domain Data Grid will be easier to use, more scalable, more flexible and ideally suited for cloud environments and cloud-native architectures. All Payara Server instances will join a single domain-wide data grid for sharing of in-memory data like web sessions, JCache, SSO and Stateful EJBs.

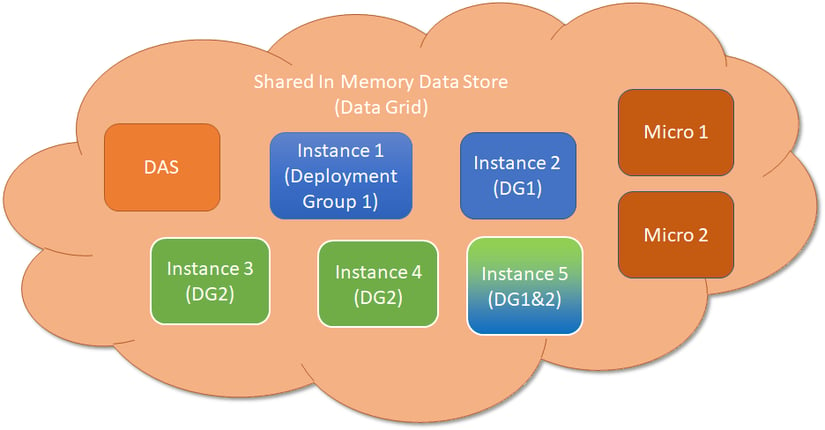
Previously in Payara Server 4, the concepts of data sharing, instance configuration and deployment targeting were all wrapped into one concept "the Cluster". In Payara Server 5, to provide flexibility, greater compatibility with the cloud and ease of use, we are separating these concerns. In Payara Server 5, all Payara Server instances in a domain will form a single domain-wide data grid and data will be shared across all instances transparent to the developer. This data grid, in the majority of cases, will require zero or very little configuration - it will just happen. Data stored in the grid is duplicated across 1 or more instances for high availability and the more instances that are added the more JVM Heap is available for in-memory data storage. This allows the grid to scale to large data sets by adding more Payara Server or Payara Micro instances without loss of performance on updates or retrievals.
For targeting of deployments, we will introduce a new concept simply called 'deployment groups'. A deployment group will be a set of Payara Server instances that can be used for targeting of resources and deployments and start/stop operations. Individual Payara Server instances will be able to be in zero, 1 or many deployment groups providing greater flexibility over traditional clustering. In addition, Payara Micro instances will also be able to join the Data Grid and a new domain mode clustering option has been added to the Payara Micro command line flags.
For cloud environments, there is no requirement to use Multicast for discovery of grid members. The data grid uses knowledge of the domain topology to find and discover other servers during boot and to join the grid. This eliminates complex configuration on cloud environments. We have tested this on major cloud IAAS platforms including Google Cloud Platform, Microsoft Azure and Amazon AWS and in all these of environments the Data Grid is formed with no configuration required.
For those familiar with Payara Server 4, this means the old Shoal clusters, GMS and the old Hazelcast configuration has gone to be replaced with the new Data Grid.
Introducing the Data Grid in Payara Server 5 enables us to build and expand exciting new technologies like the Clustered CDI Events, light-weight domain messaging and Data Grid CDI singletons.
We have lots of plans and are really excited by this evolution of the humble cluster!

Related Posts
The Payara Monthly Catch - August 2025
Published on 02 Sep 2025
by Dominika Tasarz
0 Comments

Welcome aboard the August 2025 issue of The Payara Monthly Catch! With summer in full swing, things may have felt a little more quiet across the Java world - but certainly not less interesting! We hope you managed to get some rest and recharge, ...
How to Build Cost-Effective Cloud Architectures
Published on 19 Aug 2025
by Chiara Civardi
0 Comments

Cloud adoption has transformed how developers build and scale applications, but it also brings new challenges in controlling costs. As cloud bills grow alongside usage, designing cost-efficient cloud architectures becomes essential for ...