
Posts tagged domain data grid
Using Hazelcast SQL with Payara Micro
Published on 27 Sep 2021
by Rudy De Busscher
Topics:
Payara Micro,
Hazelcast,
Clustering,
domain data grid
|
0 Comments

Co Authored with Nicolas Frankel (Hazelcast Developer Advocate), this article is also available as a PDF.
The Hazelcast In-Memory Data Grid (IMDG) is an efficient method of storing data in a distributed way within the memory of the different processes of the cluster. Because it is distributed, searching the data locally requires 'moving' the data to your instance so it can be accessed, which is not overly efficient. Hazelcast SQL allows distributed queries which perform the search where the data is, and then transfers only the results to your process. Since the Payara products already use Hazelcast IMDG, using the Hazelcast SQL capabilities is straightforward: just add the additional JAR library to start using it.
Real-World Use Case: Robust and Flexible Batch Processing with Payara Platform
Published on 09 Sep 2021
by Ondro Mihályi
Topics:
Payara Enterprise,
domain data grid,
use case
|
0 Comments
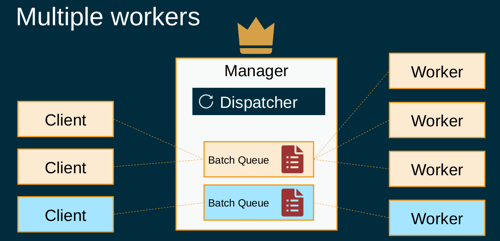
One of the Payara Platform features people like most is flexibility for how it can run applications and services and connect them to each other. You can run applications on Payara Server, Payara Micro, and cluster them all together in the same Domain Data Grid, while using the same technology for building the applications and the samefeatures in both Payara Platform runtimes. A lot of our customers take advantage of this flexibility and some even take to the extreme, as described below.
How to Create a Domain Data Grid and Use With a Load Balancer
Published on 29 Oct 2018
by Kenji Hasunuma
Topics:
Payara Micro,
Microsoft Azure,
Payara Server 5 Basics,
domain data grid
|
4 Comments

In this video demo we show you how to use the Domain Data Grid which was introduced as a new feature in Payara 5. As well as further demos using Payara Server and Payara Micro on Microsoft Azure.
Domain Data Grid in Payara Server 5
Published on 23 Jan 2018
by Steve Millidge
Topics:
Microservices,
Hazelcast,
Clustering,
Scalability,
Cloud,
Amazon Cloud,
Cloud Connectors,
Payara Server 5,
Cloud-native,
domain data grid
|
0 Comments
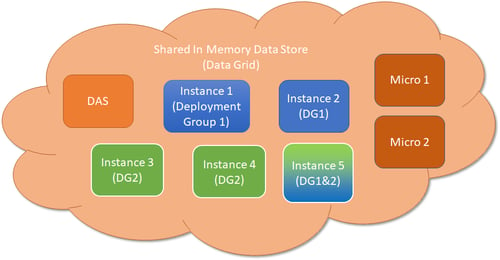
In Payara Server 5 we will be introducing some major changes to the way clustering is working by creating the Domain Data Grid (see documentation for more info). The Domain Data Grid will be easier to use, more scalable, more flexible and ideally suited for cloud environments and cloud-native architectures. All Payara Server instances will join a single domain-wide data grid for sharing of in-memory data like web sessions, JCache, SSO and Stateful EJBs.
