
Published on 09 Sep 2021

One of the Payara Platform features people like most is flexibility for how it can run applications and services and connect them to each other. You can run applications on Payara Server, Payara Micro, and cluster them all together in the same Domain Data Grid, while using the same technology for building the applications and the samefeatures in both Payara Platform runtimes. A lot of our customers take advantage of this flexibility and some even take to the extreme, as described below.
One of the best examples of leveraging this flexibility is a project of one of our Payara Enterprise customers. They built their own solution to optimize running a vast amount of batch jobs in a robust and effective way.
Their solution is based on standard Jakarta EE technologies and deployed on a combination of Payara Server and Payara Micro instances that fits the need of the individual components. The main application services are running on Payara Server instances, which offer easier access to management and monitoring features. On the other hand, small utility services are designed to be ephemeral, scalable and easily replaceable - so each of these are set up to run on their own dedicated Payara Micro runtime to shorten the startup time and decrease the amount of resources that each separate service needs.
This configuration helps to overcome the following challenges:
- Need to process a lot of transactions quickly and reliably
- Need to distribute the load
- Need to control all processes and recover from failures
- Ability to deploy, run, and scale the system in a cloud environment without issues
Why Batch Processing?
Typical batch jobs run for a long time, sometimes need to be reconfigured during processing without redeployment, and they process huge amounts of data in chunks. Batch processing is a sharp contrast to real-time processing, which should respond immediately and fast - and the application should be always ready to respond, ideally without any delay or downtime.
Most of the small utility services execute batch jobs that shouldn't impact the real-time flow of the critical application services. That's why they are designed to run separately, isolated from the critical services. Batch jobs are very different from real-time and interactive processing. Instead of executing activity based on requests, events, or human interaction, the batch jobs may be scheduled and executed regularly during quiet periods or postponed until quite periods when there are more resources available to finish the job.
Payara Platform supports writing and executing batch jobs using the Jakarta Batch API (previously known as JBatch and JSR 352). Jakarta Batch is a full-fledged batch execution framework. It supports both simple and complex batch execution flow, which can contain multiple steps executed sequentially or in parallel, forking the flow or joining parallel flows. Individual steps written in Java are wired together into a flow using XML-based Job Specification Language. This is a small example of such job specification:
<?xml version="1.0" encoding="UTF-8"?>
<job id="testjob" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<properties>
<property name="outfile" value="output.txt"/>
</properties>
<step id="teststep">
<batchlet ref="SimpleBatchlet"/>
</step>
</job>This job specification refers to a "batchlet", which is a step represented by a CDI bean with the name SimpleBatchlet given by the @Named annotation:
@Dependent
@Named("SimpleBatchlet")
public class SimpleBatchlet implements Batchlet {
// implementation
}Coordinating Batch Execution Across Worker Microservices
Our customer's project requires that the system is robust and tolerant to failures. In case of any failure, due to erroneous input data, defects in the application, or in case of a hardware or network failure, the system needs to be able to recover, continue the operation, and complete all processing. Another requirement is that batch processing shouldn't impact critical services, which need to stay operational at all costs. That's why batch processing should gracefully degrade if the resources are needed to keep the critical services fully operational, and process the batch jobs at a later time.
For these reasons, our customer developed a solution based on many batch job workers running on separate instances of Payara Micro as standalone Java microservices. They can be easily launched and stopped when needed and execute any batch job in the queue. The number of workers can be increased if there are enough resources and there are many tasks in the queue, or decreased if resources are needed by the critical services or when there are fewer tasks to process.
A single instance of a batch job manager, which runs on Payara Server, receives requests for executing batch tasks from external clients, keeps queues of batch tasks, and dispatches tasks from the queues to available workers. 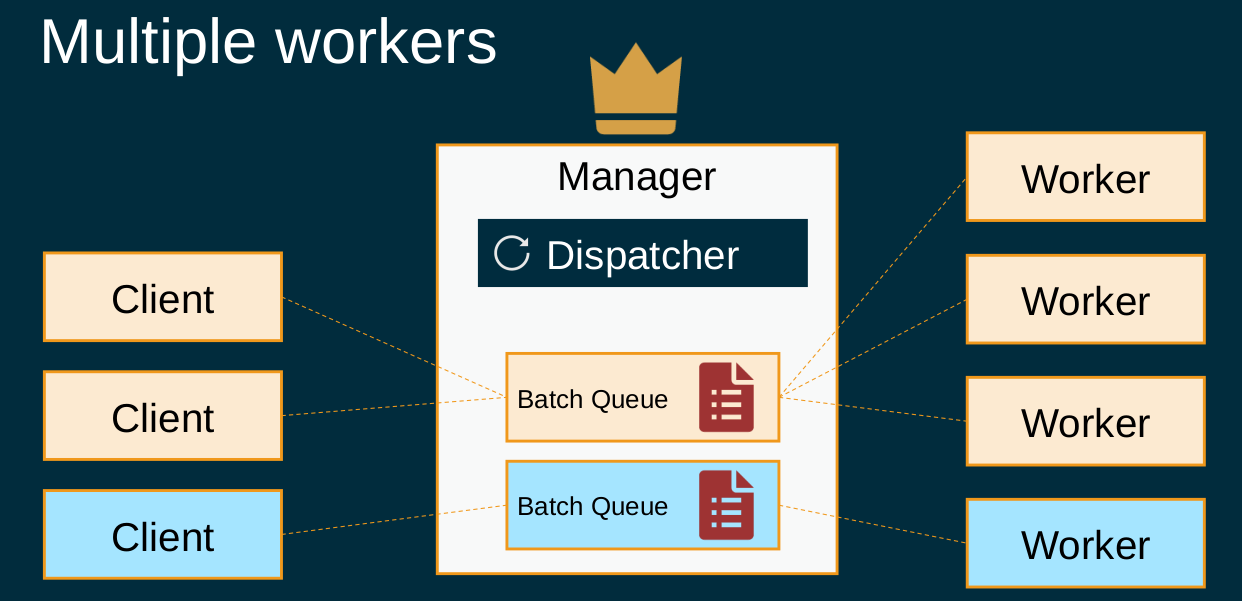
The communication between the manager and workers happens via REST calls implemented using Jakarta RESTful Web Services API (previously known as JAX-RS). The communication is asynchronous to minimize the risk that an unresponsive worker could slow down or impact other processing. Instead of waiting for a response, the manager just starts a new batch job on a worker with a REST call that produces an immediate response. The worker only responds with a confirmation that the instruction is received and batch processing has started. The manager then regularly polls the worker via other REST calls. If the batch execution hasn't completed yet, the worker just responds immediately with the information of whether the job has already completed or not. In case it's completed, the worker also sends a report about the job execution and it's again ready to receive another batch task.
The Benefits of Separating Batch Jobs to Standalone Microservices
Separating the execution of batch jobs to standalone microservices is a perfect example of how the microservices pattern helps reduce the risk of failures and recover from any failures that can happen. It allows to scale worker microservices separately from the critical services, and even safely restart the services in case of a failure, without having to restart the critical services. Any failure that happens in a microservice is isolated from the critical services and doesn't impact real-time processing.
Payara Platform Enterprise made it easy for this organization to implement their solution. It provides the Payara Micro runtime, which is ideal for running small microservices launched from command line as needed. Multiple services can run on the same machine on a different port, which is either specified on command line or automatically detected by Payara Micro itself. Both Payara Server and Payara Micro support the same set of features and programming APIs, so it's easy to develop applications that run on them using the same tools and within the same development team. Therefore, it's not only easy to configure and manage such a solution with Payara Platform in production, but it's also easy and straightforward to develop, deploy, test and debug the application in a development environment without unnecessary complexity, right from any Java IDE.
See How Other Customers are Using the Payara Platform Here:

Related Posts
The Payara Monthly Catch - August 2025
Published on 02 Sep 2025
by Dominika Tasarz
0 Comments

Welcome aboard the August 2025 issue of The Payara Monthly Catch! With summer in full swing, things may have felt a little more quiet across the Java world - but certainly not less interesting! We hope you managed to get some rest and recharge, ...
The Payara Monthly Catch - July 2025
Published on 31 Jul 2025
by Chiara Civardi
0 Comments
Your Round-Up of the Latest Java & Jakarta EE News.
Welcome aboard the July issue of The Monthly Catch. As always, we’re bringing you the latest updates, product news and expert resources from across the Payara ecosystem.
This month, we’re ...