
Posts from Rudy De Busscher
.jpg)
Should you use OpenShift to Run Payara in the Cloud?
Published on 28 Jan 2022
by Rudy De Busscher
0 Comments

The world is moving to containerized workflows. As a result, tools to handle containerization become more and more important.
Kubernetes is the most widely used platform for managing and orchestrating containers. But since it contains only the basic building blocks, you need additional tools if you want to set up your environment for running applications on it.
In this blog, we take a closer look at Red Hat OpenShift and the comparison with Kubernetes.
What Is Payara Embedded?
Published on 07 Jan 2022
by Rudy De Busscher
Topics:
Payara Platform 5,
Payara Embedded
|
0 Comments

The Payara Platform contains many products and some you may not have heard of! For example, have you heard of Payara Embedded Full Profile or Payara Embedded Web Profile?
Getting Started with Jakarta EE 9: Jakarta Validation
Published on 30 Nov 2021
by Rudy De Busscher
Topics:
JakartaEE,
getting started with Jakarta EE
|
0 Comments

In this last blog of the Getting Started with Jakarta EE 9 blog and video series, we have a look at the Bean Validation specification. Using this specification, you can define some validation rules, from some simple ones on a single field to very complex ones on a business entity, that are reusable depending on the input frameworks you are using within your application.
JDK17 Support in Payara Community
Published on 25 Nov 2021
by Rudy De Busscher
Topics:
New Releases,
JDK 17
|
2 Comments

JDK 17 is the latest Long Term Supported (LTS) version of the Java platform, released in September 2021. LTS versions will have regular releases for the coming years and you don't need to switch to a newer version after 6 months as you do with those 'interim' JDK versions.
The features in an LTS version are kept stable so it is ideal for running your enterprise applications. Once you switch to an LTS, you can safely update to any minor release to accommodate for security issues and bug fixes of the JDK platform, but without needing to perform a migration.
With the release of the November 2021 version of the Payara Platform Community Edition, Payara Server, Payara Micro, and the Web Profile run on JDK 17 platform.
Running Payara Server as a Service - Added Support for systemD on Linux
Published on 19 Nov 2021
by Rudy De Busscher
Topics:
Payara Server 5,
New Releases,
systemD
|
3 Comments

Before your application can respond to any request from the user, Payara Server needs to be started as a process on a machine. The Payara Server Domain instance or a Payara instance can be started using the Asadmin CLI tool.
But in many cases when you run Payara Server on an on-premise machine or in a virtual machine, you want to start the Payara process automatically when the machine is booted. You can do this by defining Payara as a Service on the machine.
What's New in the November 2021 Payara Platform Release?
Published on 17 Nov 2021
by Rudy De Busscher
Topics:
What's New,
New Releases
|
0 Comments
The November 2021 Payara Platform release is here! Payara Platform Enterprise 5.33.0 includes 4 improvements, 4 bug fixes, and 2 component upgrades. The Payara Platform Community 5.2021.9 release offers 11 improvements, 6 bug fixes, and 11 component upgrades.
Client Certificate Realm Configuration in Payara Server
Published on 29 Oct 2021
by Rudy De Busscher
Topics:
Security,
New Releases
|
0 Comments

A realm is the security policy domain within an application server. It defines how the authentication and authorization for your application is performed. Most of the time, your application is used by a person that can provide username and passwords as credentials (directly or indirectly through providers like an OpenId Connect provider) but some use cases exist where another process needs to use your endpoints.
Configure the Details of the GZIP Compression in Payara Platform October 2021 Release
Published on 25 Oct 2021
by Rudy De Busscher
Topics:
Payara Platform 5,
New Releases
|
0 Comments
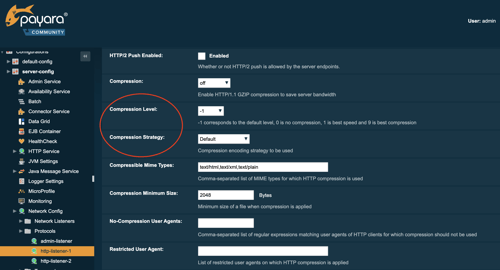
Data is sent to and received from the endpoints within Payara Platform. When large chunks of data are sent to the client in response to a request, it might be an option to compress the data when the bandwidth is limited. This speeds up the transfer, but requires more CPU on the server and the client to perform the compression and handle the response.
With the October 2021 release, the Payara Platform allows configuring the compression level and the compression algorithm so you can better tune your environment for your requirements.
Why Payara Platform Only Supports LTS Versions of JDK
Published on 29 Sep 2021
by Rudy De Busscher
Topics:
Payara Platform 5,
Java 8,
Java 11,
java 17
|
0 Comments
The next Java Long Term Support (LTS) version, Java 17, has been released. We thought this would be a good time to give you a short refresher on the Java versioning and why Payara Platform only runs on LTS versions.
Using Hazelcast SQL with Payara Micro
Published on 27 Sep 2021
by Rudy De Busscher
Topics:
Payara Micro,
Hazelcast,
Clustering,
domain data grid
|
0 Comments

Co Authored with Nicolas Frankel (Hazelcast Developer Advocate), this article is also available as a PDF.
The Hazelcast In-Memory Data Grid (IMDG) is an efficient method of storing data in a distributed way within the memory of the different processes of the cluster. Because it is distributed, searching the data locally requires 'moving' the data to your instance so it can be accessed, which is not overly efficient. Hazelcast SQL allows distributed queries which perform the search where the data is, and then transfers only the results to your process. Since the Payara products already use Hazelcast IMDG, using the Hazelcast SQL capabilities is straightforward: just add the additional JAR library to start using it.