
Posts from Jonathan Coustick

How to Deploy an Application on Payara Server 5
Published on 13 Feb 2020
by Jonathan Coustick
Topics:
Payara Server 5 Basics
|
5 Comments

This is Part 2 of our Payara Server - Back to Basics series, see Part 1 - Installing Payara Server on Ubuntu here.
In order for a web application to run, it must be first deployed on an application server such as Payara Server. Deployment in the context of web applications is the act of installing the application on a server. It allows requests to be handled and so on. This guide will provide you with a few different ways to get your application running.
Back to Basics - Installing Payara Server 5 on Ubuntu
Published on 22 Jan 2020
by Jonathan Coustick
Topics:
Payara Server 5,
JakartaEE,
Payara Server 5 Basics
|
0 Comments
This is Part 1 of our 'Payara Server- Back to Basics' series, where we will show you a step-by-step overview of how to install Payara Server 5 on Ubuntu.
New OpenTracing Features in Payara Platform 5.194
Published on 26 Nov 2019
by Jonathan Coustick
Topics:
Payara Platform 5,
New Releases,
Notifier
|
2 Comments
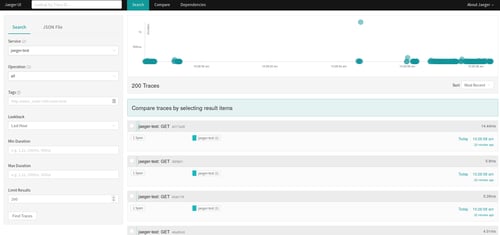
Payara Platform has implemented MicroProfile OpenTracing with its own tracer that can be sent to other sources via the notification service. But maybe you don't want to use Payara's Tracer, and instead want to use a different one - now you can, starting from Payara Platform 5.194 onwards.
Payara Platform 5.193 Supports MicroProfile Metrics 2.0
Published on 31 Oct 2019
by Jonathan Coustick
Topics:
MicroProfile,
Payara Platform 5
|
1 Comment

HK2: The Hundred Kilobyte Kernel
Published on 06 Jun 2019
by Jonathan Coustick
Topics:
Payara Platform,
HK2
|
1 Comment
.jpg?width=500&name=1045098_5242_3%20(1).jpg)
HK2 is a rather old dependency injection (DI) framework and is used as the core of Payara Server. Created in 2007 by Kohsuke Kawaguchi (who is also the creator of the Hudson project, now Jenkins) at Sun Microsystems, it followed JSR 330 closely, which was the JSR that introduced the @Inject, @Named and @Qualifier annotations, the very annotations which are also heavily used in CDI.
Did You Know? Payara Platform Can Cluster By DNS
Published on 17 Dec 2018
by Jonathan Coustick
Topics:
Hazelcast,
Clustering,
Payara Platform
|
2 Comments

Hazelcast in the Payara Platform offers several ways to configure how instances cluster. One new way is by using DNS records.
Setting Up a Data Source in Payara Micro
Published on 20 Nov 2018
by Jonathan Coustick
Topics:
Payara Micro,
Microservices
|
6 Comments

Having previously blogged about setting up data sources in Payara Server, we thought we should mention that you can also set up data sources in Payara Micro. In this blog, we'll take you through the process of setting up a data source using Payara Micro, including code snippets and where to find full code examples. Let's get started!
Payara for Beginners – Payara ServerをEclipse IDEに追加する
Published on 19 Sep 2018
by Jonathan Coustick
Topics:
Payara Server Basics,
Eclipse,
Japanese language
|
0 Comments
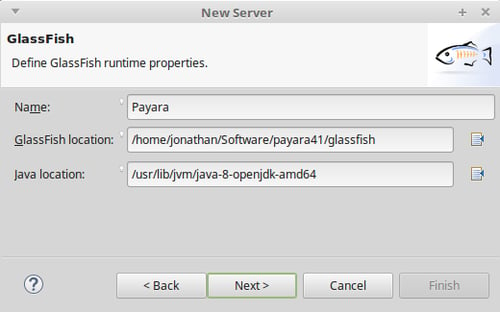
Java EEプロジェクトを作成するにあたって、Eclipseにサーバーを定義してアプリケーションをIDE上でテストできるようにしておくことは重要です。生成物をビルドして手動でPayara Serverにデプロイするよりも、作業がずっとスムーズになります。
Payara para principiantes: Añadir Payara Server a Eclipse IDE
Published on 13 Aug 2018
by Jonathan Coustick
Topics:
Payara Server Basics,
Eclipse,
Spanish language
|
3 Comments
Si estás creando un proyecto Java EE, es importante tener un servidor definido en Eclipse para poder probar fácilmente tus aplicaciones desde el IDE, lo que resulta en un flujo de trabajo más practico en lugar de construir el artefacto y desplegarlo manualmente en Payara Server.
Deploying to Payara Server Using the Maven Cargo Plugin
Published on 31 May 2018
by Jonathan Coustick
Topics:
Maven,
Payara Server
|
9 Comments

When creating a Java EE application it is important to deploy and test it on a server that is as close to the target production environment as possible. If you use Maven in your project, it is possible to do so using the Cargo plugin, which allows you to deploy an application to an instance of Payara Server either locally or remotely. A complete example is available at https://github.com/payara/Payara-Examples/blob/master/ecosystem/payara-maven/pom.xml.