
Posts tagged Payara Server Basics - Series
Basics of Payara Server Admin Console - #1 Overview and Concept
Published on 02 May 2019
by Kenji Hasunuma
Topics:
Payara Server Basics - Series
|
4 Comments
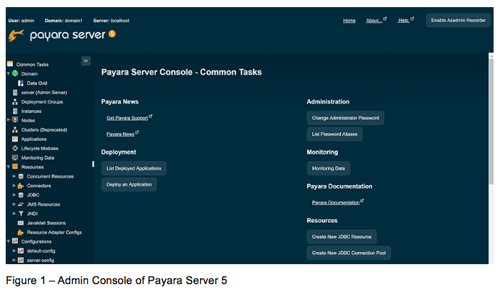
This is the first article of “Basics of Payara Server Admin Console” blog series. I’ll explain how to use Admin Console of Payara Server in this blog series. In this article, I’ll explain the concept of Admin Console and its role in Payara Server, which is important before you start using the Admin Console.
Installing Payara Server on Mac
Published on 18 Oct 2018
by Rudy De Busscher
Topics:
JVM,
Payara Server Basics - Series,
Payara Server 5 Basics
|
4 Comments

Introduction
This blog explains the setup of Payara Server on MacOS systems and how you can define a specific JVM which will be used to run the server.
Session Replication in Payara Server with Hazelcast
Published on 30 Aug 2018
by Matthew Gill
Topics:
Payara Server Basics - Series,
Payara Server 5 Basics
|
7 Comments

*Note: This blog post is an update to Dynamic Clustering and Failover on Payara Server With Hazelcast, which was written for Payara Server 4.
Introduction
This article continues our introductory blog series on setting up a simple deployment group with Payara Server, carrying straight on from our last blog where we configured sticky sessions for Payara Server.
Configuring Sticky Sessions for Payara Server with Apache Web Server
Published on 27 Aug 2018
by Matthew Gill
Topics:
Payara Server Basics - Series,
Payara Server 5 Basics
|
2 Comments

*Note: This blog post is an update to Configuring Stick Sessions for Payara Server with Apache Web Server, which was written for Payara Server 4.
Introduction
This article continues our introductory blog series on setting up a simple deployment group with Payara Server, carrying straight on from our last blog where we set up a load balancer for our deployment group.
Creating a Simple Deployment Group
Published on 24 Aug 2018
by Matthew Gill
Topics:
Hazelcast,
Clustering,
Payara Server Basics - Series,
Payara Server 5 Basics
|
5 Comments

Note: This blog post is an update to Creating a Simple Cluster, which was written for Payara Server 4.
Introduction
Continuing our introductory blog series, this blog will demonstrate how to set up a simple Hazelcast deployment group containing two instances. Deployment groups were introduced with Payara 5 to replace clusters. They provide a looser way of managing servers, allowing instances to cluster by sharing the same configuration whilst providing a single deployment target for all of them. See here to read more about Deployment Groups.
Fundamentos de Payara Server Parte 6 - Creando un cluster dinámico con conmutación por fallas en Payara Server con Hazelcast
Published on 29 May 2018
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
1 Comment
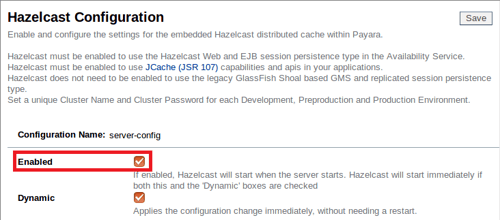
Avanzando más nuestra serie de blogs de introducción, esta entrada mostrará como puedes escalar de forma dinámica tu cluster, y como Payara Server maneja la conmutación por fallas entre miembros del cluster.
See here for the original version in English language.
La conmutación por fallas es la habilidad de continuar proporcionando acceso a nuestro sitio web o aplicación en el caso de que un servidor falle. Es una parte importante de un servicio que goza de alta disponibilidad, cuyo objetivo es minimizar los tiempos de inactividad a lo largo de tu infraestructura de servicios.
Payara Server Basics Part 7 - Creating a simple Payara Server Cluster in Windows with DCOM
Published on 08 Dec 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
Scalability,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments

Taking our introductory series onwards, this blog will look at how you set up a simple Payara Server cluster on Windows using the native remote control protocol, DCOM. We will set up two instances on Windows 10, controlled by a third Domain Administration Server (DAS) instance on Windows 7 via DCOM, and cluster them together using Hazelcast. Finally, we will deploy our trusty clusterjsp application to demonstrate how the data is being shared across our instances.
Payara Server Basics Part 6 - Dynamic Clustering and Failover on Payara Server with Hazelcast
Published on 10 Nov 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments
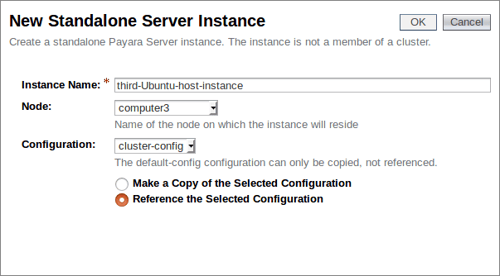
Further developing our introductory blog series, this post will look at how you can dynamically scale your cluster, and how Payara Server handles failover between cluster members.
Failover is the ability to continue to provide access to your website or application in the event of a server failing. It is an important part of high availability hosting, which aims to minimise downtime across your server infrastructure.
Payara Server Basics Part 5 - Configuring Sticky Sessions for Payara Server with Apache Web Server
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
0 Comments
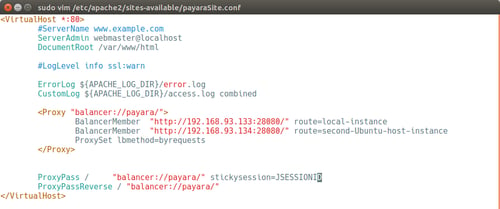
This article continues our introductory blog series on setting up a simple cluster with Payara Server, carrying straight on from our last blog where we set up load balancer on our cluster.
By clustering our Payara Servers together and balancing traffic between them with Apache Web Server we keep the benefits of having our application accessible from a single URL and gain the resilience and expansion prospects from having our application deployed across multiple instances.
Fundamentos de Payara Server Parte 5 - Configurando Sesiones Persistentes para Payara Server con Servidor Web Apache
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
0 Comments
Este artículo continúa nuestra serie de blogs de introducción para configurar un cluster con Payara Server, continuando desde nuestro último articulo donde configuramos un balanceador de carga para nuestro cluster.