
Originally published on 29 May 2018
Last updated on 29 May 2018

Avanzando más nuestra serie de blogs de introducción, esta entrada mostrará como puedes escalar de forma dinámica tu cluster, y como Payara Server maneja la conmutación por fallas entre miembros del cluster.
See here for the original version in English language.
La conmutación por fallas es la habilidad de continuar proporcionando acceso a nuestro sitio web o aplicación en el caso de que un servidor falle. Es una parte importante de un servicio que goza de alta disponibilidad, cuyo objetivo es minimizar los tiempos de inactividad a lo largo de tu infraestructura de servicios.
Requisitos
Para seguir esta entrada del blog tal y como está escrito, necesitarás:
- El cluster creado en nuestro blog anterior
- Otra máquina Ubuntu nueva con un nodo SSH configurado.
- La aplicación rest-jcache de nuestro repositorio de Ejemplos de Payara
Configurando nuestro nodo
Como anteriormente, el primer paso es crear un nodo SSH en nuestra nueva máquina. Para más detalles acerca de los nodos SSH, y porqué vamos a utilizar uno aquí, lee este blog. Para detalles sobre cómo configurar un nodo SSH en nuestra nueva máquina, dirígete a nuestro anterior blog sobre configurar un simple cluster con Payara Server.
Como puedes ver, hemos añadido un tercer nodo SSH llamado de forma apta "computer3".
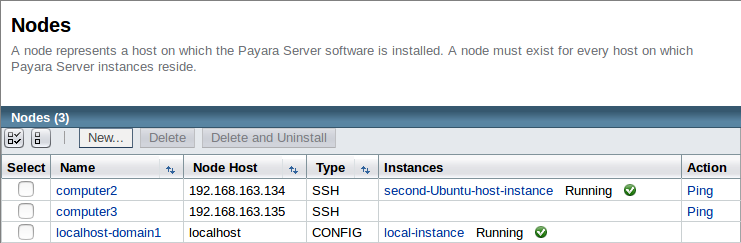
Creando una nueva instancia
Como este nodo será parte de nuestro cluster existente, lo enlazaremos de nuevo con la configuración de nuestro cluster que creamos en el blog anterior. Esta es otra ventaja de utilizar la configuración centralizada de antes; los nuevos nodos recibirán automáticamente la misma configuración de aquellos que ya están en el cluster, minimizando el trabajo que necesitaremos hacer para nuestras nuevas instancias.
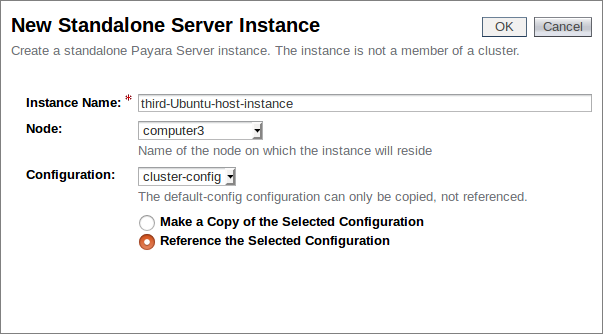
Ahora tenemos tres instancias, con nuestra "third-Ubuntu-host-instance" recién creada y con la misma configuración asignada que las otras dentro de nuestro cluster.:
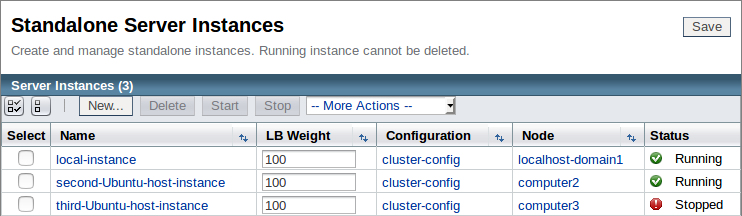
Como la configuración del cluster tiene Hazelcast habilitado, el momento en que iniciemos esta instancia debe unirse a nuestro cluster. Antes de iniciar la instancia, desplegaremos nuestra aplicación de prueba y añadiremos algunos datos de sesión
Desplegando nuestra aplicación de test
Nuevamente utilizaremos nuestra aplicación de ejemplo rest-jcache que utilizamos en el blog anterior. Esta aplicación es un servicio REST simple que utiliza la caché distribuida para almacenar los datos recibidos. Al entregar datos asociados con una llave, podemos recuperar exactamente los mismos datos de otro miembro del cluster, siempre y cuando utilicemos la misma llave en la petición enviada. Prepara y construye la aplicación, a menos que aun tengas el archivo WAR ya preparado en el blog anterior, con el comando "mvn clean install", y despliégalo en las tres instancias. Asegúrate de que marcas la opción "Availability" para habilitar el servicio de alta disponibilidad:
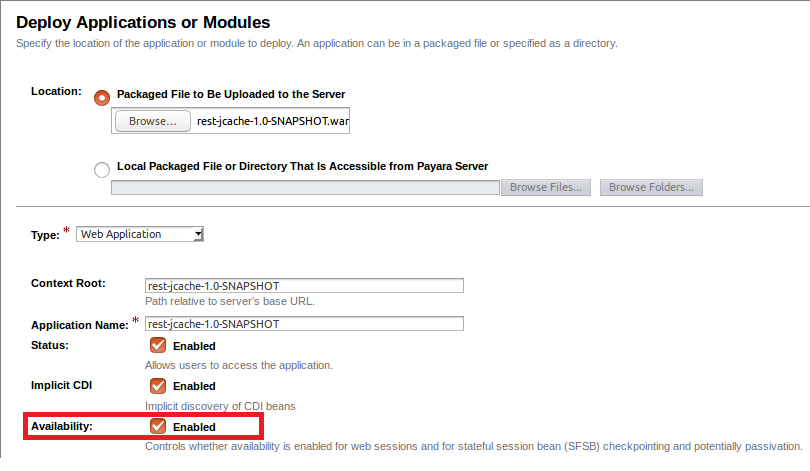
Ahora que tenemos la aplicación desplegada en las tres instancias miembros de nuestro cluster (aunque sólo dos están encendidas), comprobemos de nuevo que Hazelcast está habilitado:
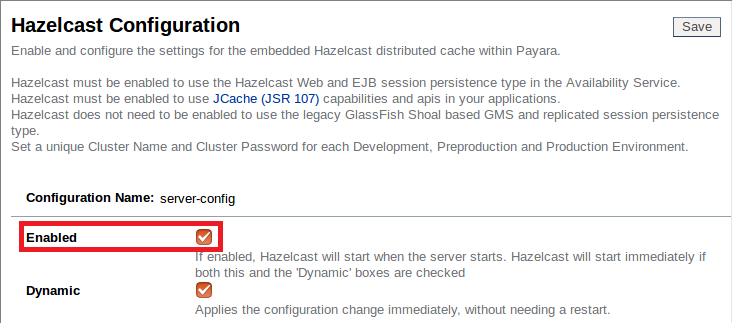
Probando nuetro cluster
Plan de prueba
Ahora que tenemos nuestras dos instancias originales en ejecuciónen ejecución, repasaremos los pasos tomados en nuestro blog anterior:
- Recuperar la llave predeterminada
- Añadir un nuevo valor para la llave "Payara"
- Recuperar este valor de la segunda instancia utilizando la llave "Payara"
Sin embargo, con este ejemplo veremos cómo reaccionarán los datos cuando se agregue un nuevo nodo y cuando otros nodos se conmuten por fallos. Una vez hayamos repasado estos puntos, a continuación realizaremos las siguientes tareas: - Iniciar nuestra tercera instancia
- Terminar nuestras instancias originales
- Reiniciar nuestras instancias originales
- Recuperar el valor de la llave "Payara" de la segunda instancia y comparar este valor con el valor de la llave predeterminada
Repasando nuestros pasos
Primero, vamos a recuperar la llave por defecto de la aplicación (para tener algo para comparar nuestro valor establecido posteriormente) con la siguiente petición curl a la instancia local:
curl "<Local Host>:<Local Instance Port>/<Application Path>?key=payara"

Así que, el valor predeterminado que deberíamos estar buscando es "helloworld". Ahora que tenemos nuestro valor predeterminado, debemos agregar un valor actual para nuestra llave en nuestra máquina local con el siguiente comando:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X PUT -d "badassfish" "http://<Máquina Localt>:<Puerto Instancia Local>/<Ruta Aplicación>?key=payara"
fish" "http://<Local Host>:<Local Instance Port>/<Application Path>?key=payara"

Hazelcast está habilitado, y nuestra aplicación está configurada para JCache, por lo que ahora podemos verificar que nuestras instancias compartan correctamente su caché enviando nuestra solicitud de curl anterior hacia nuestro segundo nodo; si funciona, en lugar de "helloworld" deberíamos recibir "badassfish":
curl "<Segunda Máquina>:<Puerto Segunda Máquina>/<Puerto Aplicación>?key=payara"

Afortunadamente también has obtenido el resultado (esperado) "badassfish". Si no es así, comprueba que las direcciones IP han sido configuradas correctamente, Hazelcast se encuentre habilitado y ¡que no hayas iniciado las pruebas de conmutación por fallas antes de tiempo!
Sufriendo un incidente de "parada"
Ahora que hemos confirmado que nuestro cluster inicial está funcionando como esperamos, podemos avanzar a nuestras nuestras pruebas de conmutación por fallas.
Volvamos a la consola de administración e iniciemos nuestra tercera instancia:
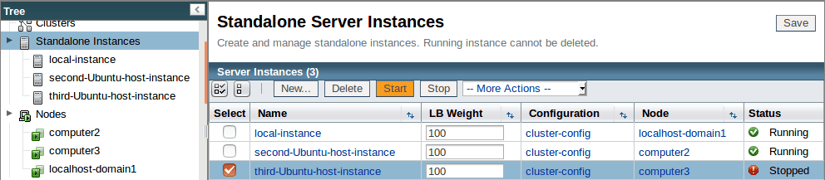
Si deseas estar tranquilo, puedes verificar que la instancia se haya unido al cluster de Hazelcast consultando la pestaña Miembros del cluster de Hazelcast:
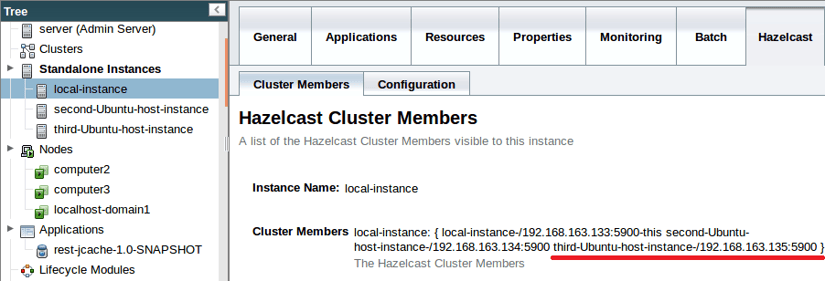
Ahora que nuestro tercer miembro se ha unido al cluster, simulemos un evento de conmutación por fallas desconectando los cables de alimentación o apagando nuestras primeras dos máquinas:
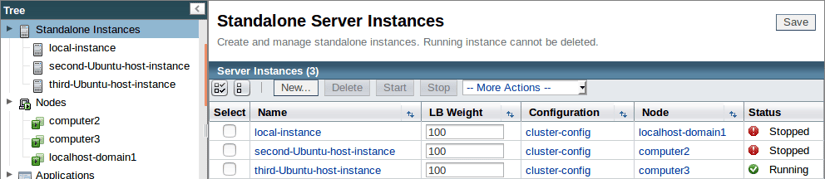
Recuperándose de un cierre inesperado
Una vez que se haya recuperado del cierre inesperado, reinicia tus instancias:
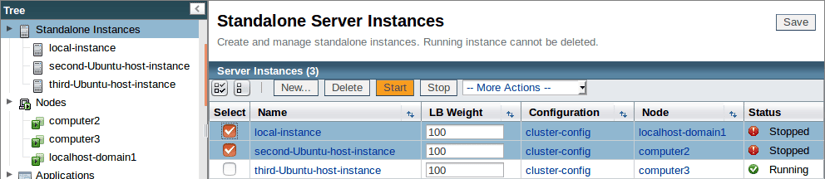
Y ahora que hemos implementado por completo nuestro plan de recuperación de desastres y reiniciado nuestras máquinas, revisaremos nuevamente el caché de la segunda instancia para confirmar que nuestros datos todavía están disponibles con el siguiente comando:
curl "<Segunda Máquina>:<Puerto Segunda Máquina>/<Puerto Aplicación>?key=payara"

Afortunadamente, como puedes ver, nuestros datos se almacenaron en caché de forma segura y, por lo tanto, pudieron conmutarse o redirigirse a causa del fallo, preservando los datos en la cache del cluster, ya que este retornó a nuestro valor original. Este es un ejemplo simple del almacenamiento en caché de Hazelcast dentro de Payara Server, pero demuestra tanto el principio de conmutación por fallos como los beneficios del alojamiento con alta disponibilidad, ya que pudimos agregar dinamicamente nuevas instancias a nuestro cluster y permitir que ellas mismas coordinen la cache entre ellas sin ningún tipo de intervención de usuario. En un entorno de producción, esto puede servir para conservar los datos almacenados en caché a través de múltiples sitios, y permitir que los usuarios continúen accediendo a las aplicaciones en caso de eventos de baja de sistema inesperados, además de permitirte un escalamiento dinámico de tu infraestructura.
Como de costumbre, si tienes algún comentario, pregunta o sugerencia, ¡no dudes de publicarlo en nuestra sección de comentarios!
See here for the original version in English language.

Related Posts
How to Kickstart Your Jakarta EE 11 Projects with Payara Starter
Published on 22 Aug 2025
by Gaurav Gupta
0 Comments

With Jakarta EE 11 now officially released, you are likely eager to explore its new capabilities but setting up your first application may take longer than you want. That’s where the latest version of Payara Starter steps in, giving you a fast, ...
How to Make Multi-Cloud Work
Published on 19 Jun 2025
by Patrik Duditš
0 Comments

Multi-cloud developments can offer real operational advantages. However, careful and strategic planning is key to maximize the gains. In fact, without clear operating models or setups, teams can experience costly missteps and cloud spent ...