
Posts from Michael Ranaldo

Fundamentos de Payara Server Parte 6 - Creando un cluster dinámico con conmutación por fallas en Payara Server con Hazelcast
Published on 29 May 2018
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
1 Comment
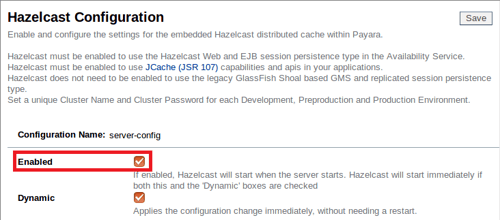
Avanzando más nuestra serie de blogs de introducción, esta entrada mostrará como puedes escalar de forma dinámica tu cluster, y como Payara Server maneja la conmutación por fallas entre miembros del cluster.
See here for the original version in English language.
La conmutación por fallas es la habilidad de continuar proporcionando acceso a nuestro sitio web o aplicación en el caso de que un servidor falle. Es una parte importante de un servicio que goza de alta disponibilidad, cuyo objetivo es minimizar los tiempos de inactividad a lo largo de tu infraestructura de servicios.
What's Coming in Payara Server 5?
Published on 07 Mar 2018
by Michael Ranaldo
Topics:
Payara Micro,
MicroProfile,
Payara Server 5,
Cloud-native
|
1 Comment

First quarter of 2018 will bring with it our long-awaited Payara 5, fresh out of Beta. Scheduled for a Q1 release (download the Release Candidate here), Payara 5 brings with it a host of improvements to Payara Server and Payara Micro. Bringing long-awaited upgrades to a raft of APIs, as well as a rethinking of the cluster concept, Payara 5 also brings us up to date with Eclipse MicroProfile 1.2 and the core functionality of GlassFish 5.

Payara Server Basics Part 7 - Creating a simple Payara Server Cluster in Windows with DCOM
Published on 08 Dec 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
Scalability,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments

Taking our introductory series onwards, this blog will look at how you set up a simple Payara Server cluster on Windows using the native remote control protocol, DCOM. We will set up two instances on Windows 10, controlled by a third Domain Administration Server (DAS) instance on Windows 7 via DCOM, and cluster them together using Hazelcast. Finally, we will deploy our trusty clusterjsp application to demonstrate how the data is being shared across our instances.
Payara Server Basics Part 6 - Dynamic Clustering and Failover on Payara Server with Hazelcast
Published on 10 Nov 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments
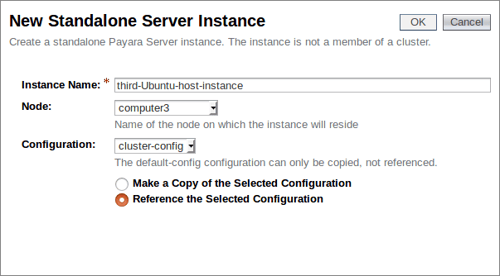
Further developing our introductory blog series, this post will look at how you can dynamically scale your cluster, and how Payara Server handles failover between cluster members.
Failover is the ability to continue to provide access to your website or application in the event of a server failing. It is an important part of high availability hosting, which aims to minimise downtime across your server infrastructure.
Payara Server Basics Part 5 - Configuring Sticky Sessions for Payara Server with Apache Web Server
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
0 Comments
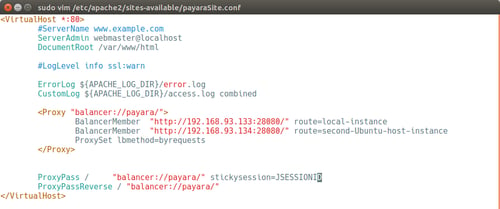
This article continues our introductory blog series on setting up a simple cluster with Payara Server, carrying straight on from our last blog where we set up load balancer on our cluster.
By clustering our Payara Servers together and balancing traffic between them with Apache Web Server we keep the benefits of having our application accessible from a single URL and gain the resilience and expansion prospects from having our application deployed across multiple instances.
Fundamentos de Payara Server Parte 5 - Configurando Sesiones Persistentes para Payara Server con Servidor Web Apache
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
0 Comments
Este artículo continúa nuestra serie de blogs de introducción para configurar un cluster con Payara Server, continuando desde nuestro último articulo donde configuramos un balanceador de carga para nuestro cluster.
Payara Server Basics Part 4 - Load Balancing Across Payara Server Instances with Apache Web Server
Published on 20 Jul 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
Scalability,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments
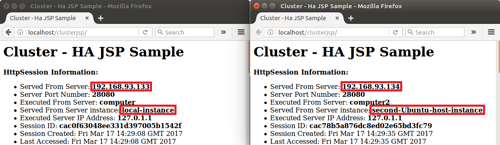
Continuing our introductory blog series, this blog will demonstrate how to add load balancing capability to Apache Web Server and forward to our simple Payara Server cluster.
A load balancer can redirect requests to multiple instances, primarily for the purpose of distributing incoming requests between cluster members based on pre-determined rules. This could be a simple "round-robin" algorithm, where the workload is distributed to each instance in turn, or a weighted algorithm where requests are delivered based on a pre-determined weight for each cluster member.
Fundamentos de Payara Server Parte 4 - Balanceo de Carga a través de Instancias de Payara Server con Servidor Web Apache
Published on 20 Jul 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
Scalability,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
0 Comments
Continuando con nuestra serie de blogs de introducción, este blog va a demostrar como añadir la capacidades de balanceo de carga a un Servidor Web Apache y asi re-enviar las peticiones HTTP a nuestro cluster de Payara Server.
What's New in Payara Server 172?
Published on 22 May 2017
by Michael Ranaldo
Topics:
What's New,
JMS,
Docker,
Cloud
|
7 Comments

This spring's silver lining, Payara Server 4.1.2.172, a highly cloud-focused release, is now available!
Focusing on enhancing Payara Server and Payara Micro's ease-of-use in cloud environments, we've brought in new features to make working with Docker more seamless and secure, native support for SaaS monitoring solutions and a huge increase in messaging capabilities for Payara Micro! Inside this quarter's release you will find 54 fewer bugs, a host of ecosystem and cloud improvements, and an update to match GlassFish 4.1.2. Carry on reading for a summary of this quarter's changes, or check out the full release notes for a complete list of changes.
Payara Server Basics Part 3 - Creating a Simple Cluster
Published on 20 Apr 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
Payara Server Basics - Series,
JCA
|
12 Comments
Continuing our introductory blog series, this blog will demonstrate how to set up a simple Hazelcast cluster of two instances.
In contrast to a development environment, where a single server is enough to act as a "proof of concept", in production it is usually necessary to look at reliably hosting your application across multiple redundant hosts to guarantee a reliable service and allow for future scaling. With Payara Server, it is possible to easily create and add instances to clusters using Hazelcast, making configuration of a distributed application a breeze.