
Originally published on 20 Apr 2017
Last updated on 15 Oct 2019

Continuing our introductory blog series, this blog will demonstrate how to set up a simple Hazelcast cluster of two instances.
In contrast to a development environment, where a single server is enough to act as a "proof of concept", in production it is usually necessary to look at reliably hosting your application across multiple redundant hosts to guarantee a reliable service and allow for future scaling. With Payara Server, it is possible to easily create and add instances to clusters using Hazelcast, making configuration of a distributed application a breeze.
Requirements
To follow along with this blog post, you will need:
- One Ubuntu host with Payara Server already installed
- One Ubuntu host with JDK 8 installed (we will install Payara Server later)
- The jcache-rest example app from our Payara Examples repository
Our first step is to create an SSH node. For more details on what an SSH node is, and why we will be using one here, read the overview blog.
Configure and Install an SSH Node with Payara Server
Once the requirements have been satisfied, our first step in creating our cluster will be configuring our second Ubuntu host ("computer2") with its own Payara Server installation and a way to communicate with our original Ubuntu host ("computer").
As both of our hosts are running a GNU/Linux OS, and we require full control of the second host, we will create an SSH node on the computer2. As part of creating the node, we will also take advantage of a very useful Payara Server feature - its ability to create a zip archive of itself and install it on a remote node (thus guaranteeing that both installations are the same and saving time).
So, the high-level steps to configure computer2 are:
- Configure it to accept SSH traffic
- Create a new SSH node in the DAS
- Have the SSH node install Payara Server
Installing an SSH server
To receive SSH traffic, computer2 must have an SSH server listening. The Ubuntu virtual machine I'm using doesn't have an SSH server installed by default, so we will install OpenSSH server from the Ubuntu repositories:
sudo apt install openssh-server
For versions of Ubuntu prior to 16.04, this would be "apt-get install"
After installing OpenSSH server, it should automatically start. Running "netstat -lnt | grep 22" should show that port 22 (the default SSH port) is now open and listening for traffic:

Creating the New SSH Node in Payara Server
Now we have SSH set up on the second Ubuntu host we can safely create the new node. On the nodes window, click the "New" button.
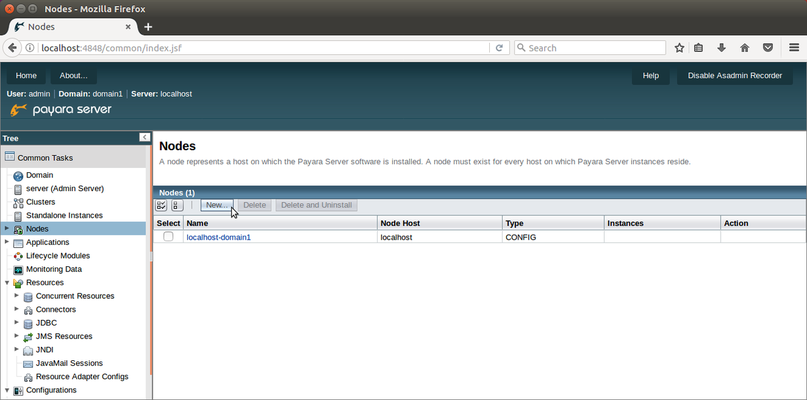
You now need to fill out the new node's properties:
- Name: Give your node a unique, descriptive name to help you identify it later. I chose computer2.
- Type: Select SSH from the dropdown menu so we can set up remote access
- Node Host: Enter the IP address for computer2.
- Install Payara Server: Enable this to automatically install Payara Server on computer2. Payara Server will create a zip archive of the local installation and copy it over to the remote node. The location of the installation can be modified by changing "Installation Directory" (which defaults to the same path as on the current host).
- SSH Port: This should be set to the SSH port - by default, 22.
- SSH User Name: This should be set to your username on the computer2.
- SSH User Authentication: For this example, we will use the password authentication, but with SSH you can also use either a key file or an alias to a password stored elsewhere.
- SSH User Password: This should be set to your password on the computer2.
With the form filled in, press the OK button. Don't worry if you see a pop-up saying "A long-running process has been detected" - there is a slight pause while it makes a copy of your Payara Server installation and installs it on the second Ubuntu host.
Once the Payara Server installation has been safely transferred, and the node created, you will be returned to the Nodes page.
Creating the New Standalone Instances
With our remote node set up, we have our foundation. We now need to configure two instances - one on each node - which will host our deployed application. We will be clustering our instances using Hazelcast rather than the legacy Shoal-based cluster, which means we need to create two "Standalone" instances which share the same configuration. We will first need to create a new configuration which they will both reference so that, like a legacy cluster, we can make a single change which takes effect on both instances.
Creating a New Configuration
To create a new configuration for our Hazelcast cluster, click on the "Configurations" parent node in the left-hand tree to go to the Configurations page, then click the "New..." button to create a new config for our cluster.
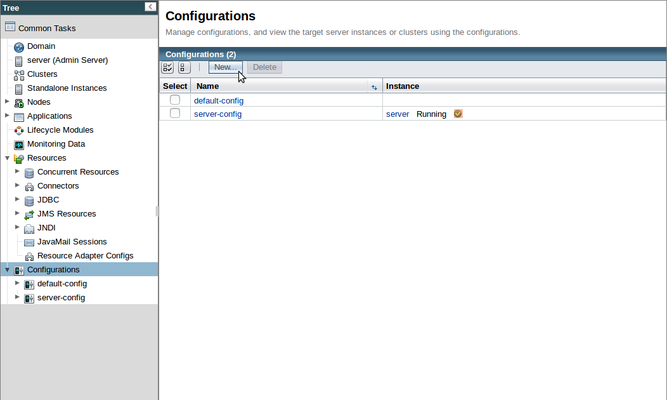
In any new installation of Payara Server, there will be two existing configurations:
- server-config is the configuration used by the Admin Server (named "server"). Changes made here will affect the DAS.
- default-config is provided for use as a template, from which other configurations can be derived. It can be used directly, but this is not advised.
Because we don't want to accidentally include any modifications we have made to the DAS configuration, we will copy the default-config and name it cluster-config.
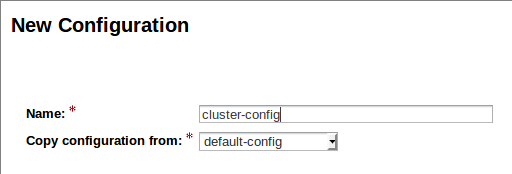
Accept the default settings and save the new configuration.
Creating a Local Standalone Instance
Next, we need to create instances which use our new configuration. To create an instance on localhost, click "New" on the Standalone Server Instances page.
On the New Standalone Server Instance page, create the instance as shown below:
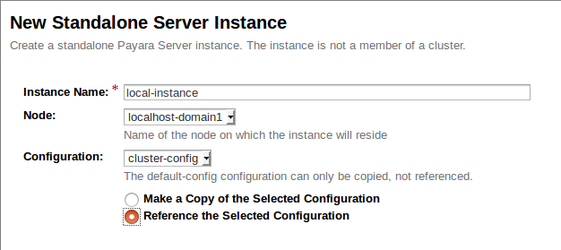
- Instance Name: I have named my instance "local-instance" so that it's clearly the one which is local to the DAS.
- Node: The localhost-domain1 node is a default node which is local to the DAS.
- Configuration: The previously created cluster-config is used here, and we need to make sure to reference it.
Press "OK" to finish creating our first instance.
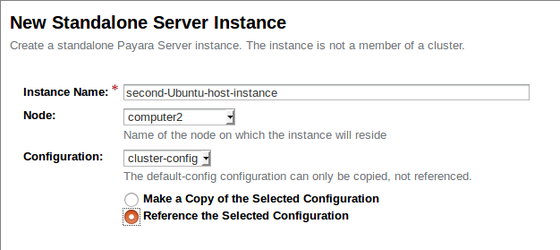
Creating a Remote Standalone Instance
We can repeat the same process as before to create an instance on the remote node simply by referring to the remote node as shown below:
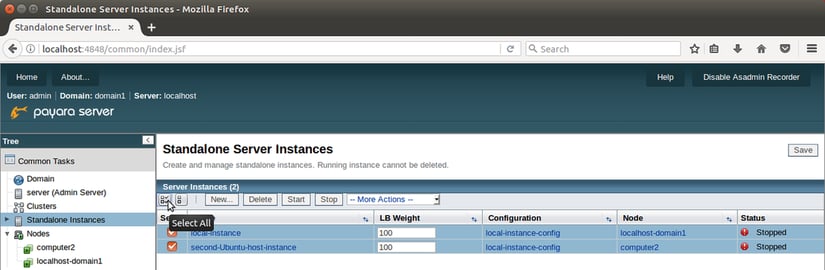
Press "OK" to create our second and final instance and to be returned to the Standalone Instances page. You should now have two instances marked as "Stopped". Select them both using the checkboxes to their left, and start them.
Enabling Hazelcast
With your instances started and referencing the same config, any change to the cluster-config will apply to both of our instances (as well as any other instances we create which reference cluster-config).
To enable Hazelcast in cluster-config, scroll down on the page tree to "Configurations" and expand "cluster-config".
Click on the Hazelcast tab, check the "Enabled" checkbox, then save.
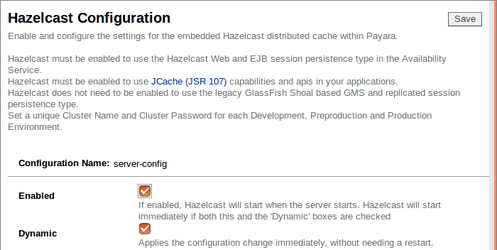
We can leave the rest of the settings at their defaults, though this does rely on UDP multicast communication being possible on our network. If you have any problems with Hazelcast's automatic discovery, then UDP multicast is something to verify.
View Hazelcast Cluster Members
If you have enabled Hazelcast with the Dynamic checkbox enabled, you should see log messages to show Hazelcast starting up and the two members discovering each other.
To view your Hazelcast cluster, select "Domain" on the page tree, then the "Hazelcast" tab, and finally the "Cluster Members" sub-tab to see the Hazelcast Cluster Members tab. Here you can see all cluster members, along with their deployed applications.
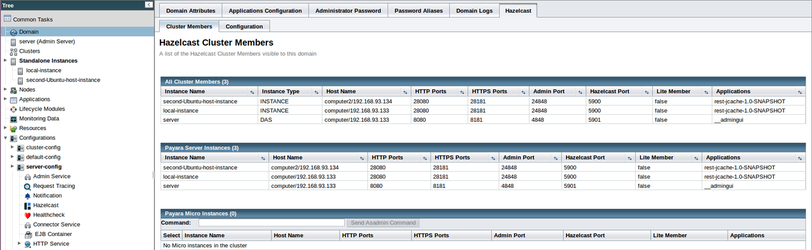
So we have our instances configured, and Hazelcast reports them as being successfully clustered, which means we are now free to test it!
Demonstrating Cache Replication
Building the Payara Example Application
The Payara Examples repository on GitHub is full of projects which demonstrate specific features available to Payara Server. We will be using the jcache-rest application to demonstrate how Hazelcast seamlessly distributes data - but first, we need to download and build it.
- To download and build the repository you will need Git and Maven installed. These are both available in the Ubuntu repositories, and can be installed with:
sudo apt install git maven
- Clone the Payara Examples repository to the first Ubuntu host with the following command:
git clone https://github.com/Payara/Payara-Examples - We are looking to build the jcache-rest example, so once you have downloaded the repository change directory to "payara-examples/javaee/jcache/jcache-rest". Note that previously, this project was located in the rest-examples/rest-jcache directory and some screenshots below still reflect it.
Once there, you can run the command "mvn clean install" to use Maven to build the project.
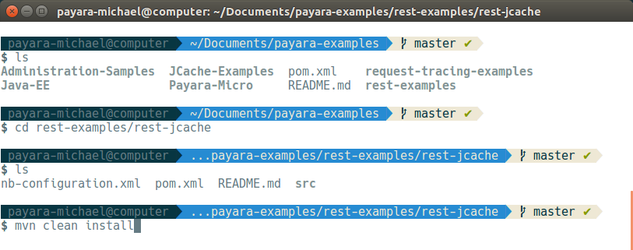
Maven will automatically download the dependencies and build the project: the compiled web application will be stored as a WAR file within the target directory.
Now that we have our test application built, we can deploy it!
Deploying the Payara Example application
To test our cluster's distributed caching ability, we will deploy the WAR application to all instances in the cluster and then add some data to demonstrate how we can modify the data within the entire cluster at the same time by editing the values in a single instance's local cache.
First, select the "Applications" page in the page tree and click on "Deploy...".
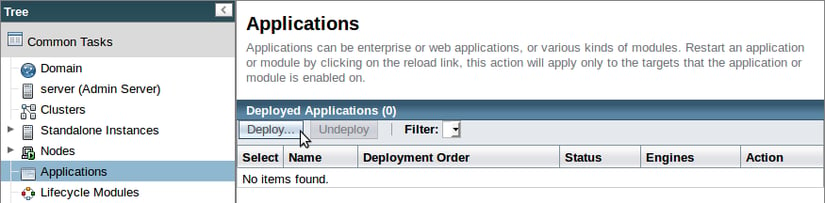
Next, upload your built application using the "Browse..." button, making sure to add both our clustered instances to the "Selected Targets":
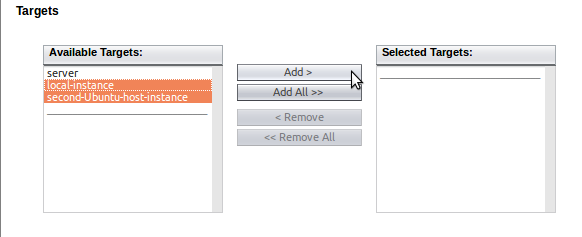
Payara Server will handle distributing the application to the instances which we selected as targets.
Testing the cluster with the Payara Example application
The jcache-rest application uses JCache API annotations on JAX-RS REST methods and listens on the "cache" endpoint backed by the CacheResource class. GET, PUT and DELETE requests are all supported:
- GET
ThegetJSON()method is annotated with@GET, so that it will be called on a GET request to the "cache" resource. The@CacheResultannotation is a JCache annotation which performs a lookup on the named cache and retrieves the cached value, if one is present, and does not execute the body of the method. On a cache miss, the method body will be entered and the string "helloworld" will be returned. In a real application, this might do a database lookup.
- PUT
TheputJSON()method is annotate with@PUT, so can be executed with an HTTP PUT request. The@CachePutannotation is used along with the@CacheKeyand@CacheValueannotations in the method signature to put the supplied value into the named cache, as before. We have used the same cache name as in the GET method, so any key which we update with a PUT will be reflected with a GET. - DELETE
In the same way as before, we have used a JAX-RS annotation (@DELETE) along with a JCache annotation (@CacheRemove) so that when an HTTP DELETE request comes in, the value which matches the key supplied will be removed from the cache.
We will first demonstrate how the second Ubuntu host has a default value of "helloworld" then, by editing the value stored within the first Ubuntu host, show how Hazelcast will automatically make the cache entry available to all members in the cluster.
1. Retrieving the default value of key "payara"
Our data is stored within the application in JSON format as key-value pairs. Retrieving a key which doesn't exist in the cache gives the default value of "helloworld", which we will receive from the second Ubuntu instance when sending the following command from our first Ubuntu instance:curl "http://<Remote_IP>:<Remote_Instance_Port>/jcache-rest-1.0-SNAPSHOT/webresources/cache?key=payara"

As you can see, there is currently no value stored for "payara" so we get the default value in return from the second instance.
2. Add a new value for key "payara" in the local instance
We can add a value to the "payara" key from our first instance with the following command:curl -H "Accept: application/json" -H "Content-Type: application/json" -X PUT -d "badassfish" "http://<Local_IP>:<Local_Instance_Port>/jcache-rest-1.0-SNAPSHOT/webresources/cache?key=payara"
 Thanks to the Hazelcast cache, this updated key-value pair will immediately be distributed across our cluster
Thanks to the Hazelcast cache, this updated key-value pair will immediately be distributed across our cluster
3. Retrieve the new value from the remote instance
we will be able to see this immediately when we re-run our original command on the second instance:curl "http://<Remote_IP>:<Remote_Instance_Port>/jcache-rest-1.0-SNAPSHOT/webresources/cache?key=payara"

And there we have it, a working Payara Server cluster, powered by Hazelcast! Now we have our cluster in place, we can start deploying our applications and making the most of our new scalability, as well as configuring our cluster for load balancing and proper session handling which will be covered in coming blogs.

Related Posts
Payara Server's High Availability Architecture: A Quick Technical Overview
Published on 05 Jun 2024
by Luqman Saeed
2 Comments

Introduction
In today's business world, competition is fierce and relentless. As a result, maximizing uptime while reducing downtime and its expenses is a top priority. In particular, users now expect applications to deliver consistent ...
Continuous Integration and Continuous Deployment for Jakarta EE Applications Made Easy
Published on 25 Mar 2024
by Luqman Saeed
1 Comment
Continuous Integration and Continuous Deployment (CI/CD) activities are designed to convey your Jakarta EE applications to end users. Thanks to the unique flexibility of Jakarta EE, multiple CI/CD options are available to software developers. ...