
Posts tagged Java EE (11)
The Payara Monthly Catch for July 2019
Published on 01 Aug 2019
by Jadon Ortlepp
Topics:
Java EE,
MicroProfile,
JakartaEE,
news and events
|
0 Comments

Another great month in the bag. There were awards, conferences, out of incubation releases, competitions, surveys and lots more going on. Below you will find a curated list of some of the most interesting news, articles and videos from this month. Cant wait until the end of the month? then visit our twitter page where we post all these articles as we find them!
The Payara Monthly Catch for June 2019
Published on 04 Jul 2019
by Jadon Ortlepp
Topics:
Java EE,
MicroProfile,
JakartaEE,
news and events
|
0 Comments

Another very busy month for the Payara team! We had our annual "Payara Week" where we fly everyone in the company to our UK HQ for a week of close collaboration, celebration, review and fun! We also announced our new partner program "Payara Radiate".
The Cloud is Driving the Future of the Java Ecosystem and Jakarta EE: Eclipse Foundation Survey Results
Published on 09 May 2019
by Debbie Hoffman
Topics:
Java EE,
JakartaEE
|
1 Comment

The 2019 Jakarta EE developer survey results are in - and they show cloud deployments have increased since last year with 62% of Java developers currently building or planning cloud native architectures within the year.
Jakarta EE 8 and Beyond
Published on 03 May 2019
by Steve Millidge
Topics:
Java EE,
JakartaEE
|
2 Comments

Today the Eclipse Foundation have announced an Update on Jakarta EE Rights to Java Trademarks which has dramatic implications for the future of Java EE and Jakarta EE. The Payara team have only recently learned about this - so we thought we would blog about how we feel this impacts customers and users of the Payara Platform. We'll also give our thoughts on how Jakarta EE should evolve given the constraints outlined in Mike Milinkovich's blog from the Eclipse Foundation.
EE Security in Relation to JASPIC, JACC and LoginModules/Realms
Published on 16 Apr 2019
by Arjan Tijms
Topics:
Java EE,
Security,
JakartaEE,
Java 8
|
2 Comments
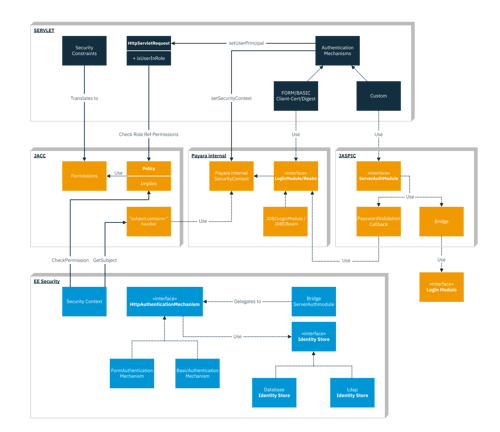
Java EE 8 introduced a new API called the Java EE Security API (see JSR 375) or "EE Security" in short.
This new API, perhaps unsurprisingly given its name, deals with security in Java EE. Security in Java EE is obviously not a new thing though, and in various ways it has been part of the platform since its inception.
So what is exactly the difference between EE Security and the existing security facilities in Java EE? In this article we'll take a look at that exact question.
Help Us Shape Your Journey to the Cloud!
Published on 08 Mar 2019
by Steve Millidge
Topics:
Java EE,
Cloud,
Cloud-native,
Microsoft Azure
|
0 Comments

One of our key goals for the Payara Platform is to enable developers to use the Java EE skills they have honed over many years to take advantage of new infrastructure, architectures and programming models. We fundamentally believe that a managed runtime platform combined with industry standard APIs like Java EE and in the future Jakarta EE is a perfect fit for cloud and containerized infrastructure. Java EE has always separated the development of applications from the construction and management of the infrastructure to run those applications using the concept of deployment artifacts. This has a natural fit to cloud and container platforms including in the future serverless models.
Glassfish 5.1 Release Marks Major Milestone for Java EE Transfer
Published on 29 Jan 2019
by Arjan Tijms
Topics:
Java EE,
GlassFish,
JakartaEE
|
3 Comments
.jpg?width=500&name=glassfish2%20(1).jpg)
Today Eclipse GlassFish 5.1 has been released, and unlike the modest increase in version number might suggest, this truly marks a major milestone. Not just for the GlassFish project itself, but for Java EE and moving Jakarta EE forward even more.
Gradual Migration from Java EE to MicroProfile
Published on 15 Jan 2019
by Rudy De Busscher
Topics:
Java EE,
Payara Micro,
Microservices,
MicroProfile
|
0 Comments
The goal of MicroProfile.IO is to optimise Java EE for a micro-service architecture. It is based on some of the Java EE specifications and standardise a few technologies from the micro-services space.
Did You Know? Asynchronous REST Requests and Responses with Java EE and MicroProfile
Published on 04 Jan 2019
by Ondro Mihályi
Topics:
Java EE,
REST,
MicroProfile
|
2 Comments
Java EE 8 fully supports asynchronous handling of REST requests and responses, on both client and server side. This is useful to optimize throughput of an application or even when adopting reactive principles. MicroProfile type-safe REST client API also supports this concept to allow you to call REST services asynchronously with a much more straightforward way with plain Java interfaces.
10th Anniversary of Java2Days - Payara Services Had to Be There!
Published on 12 Dec 2018
by Ondro Mihályi
Topics:
Java EE
|
0 Comments

I've been to Sofia, Bulgaria, a couple of times already. It all started with the Java2Days organizers inviting the Payara team to give a talk 2 years ago. But this time it was something special. The organizers joined forces with other IT conferences and prepared a special edition for its 10th anniversary in what is probably the largest building in Bulgaria - the National Palace of Culture.