
Archive from November 2017
Log directly to Logstash from Payara Server
Published on 30 Nov 2017
by Patrik Duditš
Topics:
Java EE,
JVM
|
0 Comments

(Guest blog)
When running multiple instances of an application server, it is quite hard to see correlations between events. One of the best tools to enable that is the ELK stack - Elasticsearch for building fulltext index of the log entries, Logstash for managing the inflow the events, and Kibana as a user interface on top of that.
Solutions for Payara Server exist, that use better parseable log format which can be then processed by Logstash Filebeat in order to have these log entries processed by a remote Logstash server.
In our project, we chose a different path — we replaced all logging in the server and our applications with Logback, and make use of the logback-logstash-appender to push the events directly to Logstash over a TCP socket. The appender uses LMAX disruptor internally to push the logs, so the processes does not block the application flow. This article will show you how to have this configured for your project as well.
AWS Native Discovery with Payara Micro
Published on 23 Nov 2017
by Mike Croft
Topics:
Java EE,
Payara Micro,
Microservices,
Hazelcast,
Caching,
Cloud,
Amazon Cloud,
Uber JAR,
Cloud-native
|
1 Comment

Both Payara Server and Payara Micro can cluster together and share data using Hazelcast. Out-of-the-box, there is no configuration needed, since Hazelcast uses multicast to discover and join other cluster members. However, when running in cloud environments like AWS, for example, there are a lot of things which can stop discovery being quite so straightforward. The key thing is that Multicast is not available, meaning another discovery strategy is needed; the most common generic alternative is to use TCP, but this assumes that you know at least the intended subnet that your cluster members will be in ahead of time.
Eclipse MicroProfile: a quest for a lightweight and modern enterprise Java platform
Published on 21 Nov 2017
by Mike Croft
Topics:
Java EE,
Microservices,
MicroProfile
|
0 Comments

Do you still think that Java EE is heavy-weight, cumbersome and doesn’t keep up with modern trends? I’ll show you that there are already production-ready enterprise and open source solutions to bring more flexibility than the traditional Java EE servers from the past. They strive to provide lightweight and extensible runtimes to power microservices, cloud deployments and reactive architectures already. Their individual efforts are naturally followed by an open collaboration within the MicroProfile project.
What's new in Payara Server & Payara Micro 174?
Published on 15 Nov 2017
by Jonathan Coustick
Topics:
What's New,
MicroProfile,
JMX
|
4 Comments

Payara Server Basics Part 6 - Dynamic Clustering and Failover on Payara Server with Hazelcast
Published on 10 Nov 2017
by Michael Ranaldo
Topics:
Hazelcast,
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
3 Comments
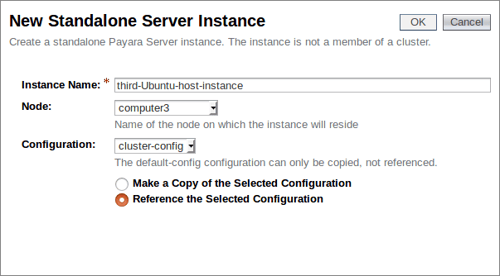
Further developing our introductory blog series, this post will look at how you can dynamically scale your cluster, and how Payara Server handles failover between cluster members.
Failover is the ability to continue to provide access to your website or application in the event of a server failing. It is an important part of high availability hosting, which aims to minimise downtime across your server infrastructure.
Welcome to the Team - Kenji Hasunuma
Published on 08 Nov 2017
by Dominika Tasarz
Topics:
What's New,
Java EE
|
0 Comments

We’re very excited to announce our new Payara Team member - Kenji Hasunuma - who joined us at the beginning of November! If you've been an active Java EE & Payara community member in Japan I'm sure you recongnize his name :)
Read along to find out more about Kenji and what he’ll be working on at Payara.
Payara Server および Payara Micro 174 がリリースされました
Published on 06 Nov 2017
by Jonathan Coustick
Topics:
What's New,
MicroProfile,
JMX,
Japanese language
|
0 Comments
Qué novedades trae Payara Server & Payara Micro 174?
Published on 06 Nov 2017
by Jonathan Coustick
Topics:
What's New,
MicroProfile,
JMX,
Spanish language
|
0 Comments
Payara Server Basics Part 5 - Configuring Sticky Sessions for Payara Server with Apache Web Server
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer
|
0 Comments
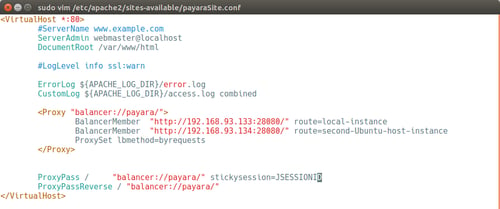
This article continues our introductory blog series on setting up a simple cluster with Payara Server, carrying straight on from our last blog where we set up load balancer on our cluster.
By clustering our Payara Servers together and balancing traffic between them with Apache Web Server we keep the benefits of having our application accessible from a single URL and gain the resilience and expansion prospects from having our application deployed across multiple instances.
Fundamentos de Payara Server Parte 5 - Configurando Sesiones Persistentes para Payara Server con Servidor Web Apache
Published on 01 Nov 2017
by Michael Ranaldo
Topics:
Payara Server Basics,
Clustering,
How-to,
GlassFish basics,
JVM,
Apache,
Payara Server Basics - Series,
Developer,
Spanish language
|
0 Comments
Este artículo continúa nuestra serie de blogs de introducción para configurar un cluster con Payara Server, continuando desde nuestro último articulo donde configuramos un balanceador de carga para nuestro cluster.