
Posts tagged Payara Micro (3)
Request Tracing in Payara Micro
Published on 13 Jun 2024
by Luqman Saeed
Topics:
Payara Micro
|
0 Comments

In a previous blog post, we explored the benefits of using Request Tracing in Payara Server. Payara Micro streamlines the configuration process, allowing you to tailor request tracing directly through command-line options. Let's have a look at how you can customize this tool for your Payara Micro applications.
The Payara Monthly Catch - May 2024
Published on 29 May 2024
by Chiara Civardi
Topics:
Java EE,
Payara Micro,
Microservices,
JakartaEE,
Payara Server,
New Releases,
Payara Events,
Payara Enterprise,
Payara Community,
Payara Cloud
|
0 Comments

Avast ye, Payara Community! We are ready to chart our course for new horizons in June, but before we do, let's take a moment to look at all the treasures our old salts developed to power up your Java and Jakarta EE applications. We've collected the best pearls and gems in our latest roundup - check them out now!
The Payara Monthly Catch - April 2024
Published on 29 Apr 2024
by Chiara Civardi
Topics:
Java EE,
Payara Micro,
Microservices,
JakartaEE,
Payara Server,
New Releases,
Payara Events,
Payara Enterprise,
Payara Community,
Payara Cloud
|
0 Comments
All aboard, Payara Community! It's time to hoist the sails and set course for new adventures in May. But before we do, let's take a look back at the treasures we uncovered in April. We've gathered our favorite catches from the depths to share with you, ready to power up your Jakarta EE applications and propel you towards success! Join us as we navigate through the highlights of the month in our latest roundup
How To Administer Payara Server From The Command Line With asadmin
Published on 26 Apr 2024
by Andrew Pielage
Topics:
Payara Micro,
Payara Server
|
0 Comments

Introduction
The asadmin Command Line Interface (CLI) is a mean of controlling Payara Server from the command line (or terminal, if you prefer). It allows you to start, stop or edit the server in a number of ways. While to some the administration console is the go-to for any administration that needs to be done, the CLI can be a potentially quicker and easier way of performing any administration tasks, particularly when dealing with headless servers, i.e. a server without a GUI.
Streamlining Payara Micro Development with Dev Mode
Published on 24 Apr 2024
by Gaurav Gupta
Topics:
Maven,
Payara Micro,
IntelliJ,
payara starter
|
3 Comments

Introduction
Payara Micro, a lightweight and flexible microservices runtime platform, offers a seamless development experience through its Maven plugin. In this guide, we'll explore the Dev Mode of Payara Micro Maven plugin, focusing on the dev goal. This goal is tailored to streamline development by enabling various features for an efficient workflow.
Stratospheric Developer Productivity - Unveiling Payara Dev Mode
Published on 19 Apr 2024
by Chiara Civardi
Topics:
Maven,
Payara Micro,
DevOps,
Payara Platform,
Java,
Jakarta EE
|
0 Comments
Development productivity is crucial in Enterprise Java and Jakarta EE application development, supporting the delivery of high-quality software solutions quickly and efficiently. As a result, it is necessary to focus on streamlining development processes, optimizing resource utilization and empowering developers to work more effectively. Payara Micro Maven Plugin, Version 1, introduces a powerful tool – Dev Mode – designed to supercharge your development experience with Payara Micro.
In our latest User Guide - available to download here - we look at this plugin, exploring its features, configurations and usage to help developers unlock stratospheric levels of productivity.
The Payara Monthly Catch - March 2024
Published on 29 Mar 2024
by Chiara Civardi
Topics:
Java EE,
Payara Micro,
Microservices,
JakartaEE,
Payara Server,
New Releases,
Payara Events,
Payara Enterprise,
Payara Community,
Payara Cloud
|
0 Comments
/wellness%20wednesday/wellness-wednesday-jess-1.jpg?width=500&name=wellness-wednesday-jess-1.jpg)
Ahoy, Payara Community! Here's an overview of our fresh catch for March, where we've reeled in our favorite bits from the depths for you to enjoy and power up your Jakarta EE applications!
Detect Slow SQL Queries With Payara Slow SQL Logger
Published on 22 Mar 2024
by Luqman Saeed
Topics:
Payara Micro,
Payara Enterprise,
Payara Community
|
0 Comments
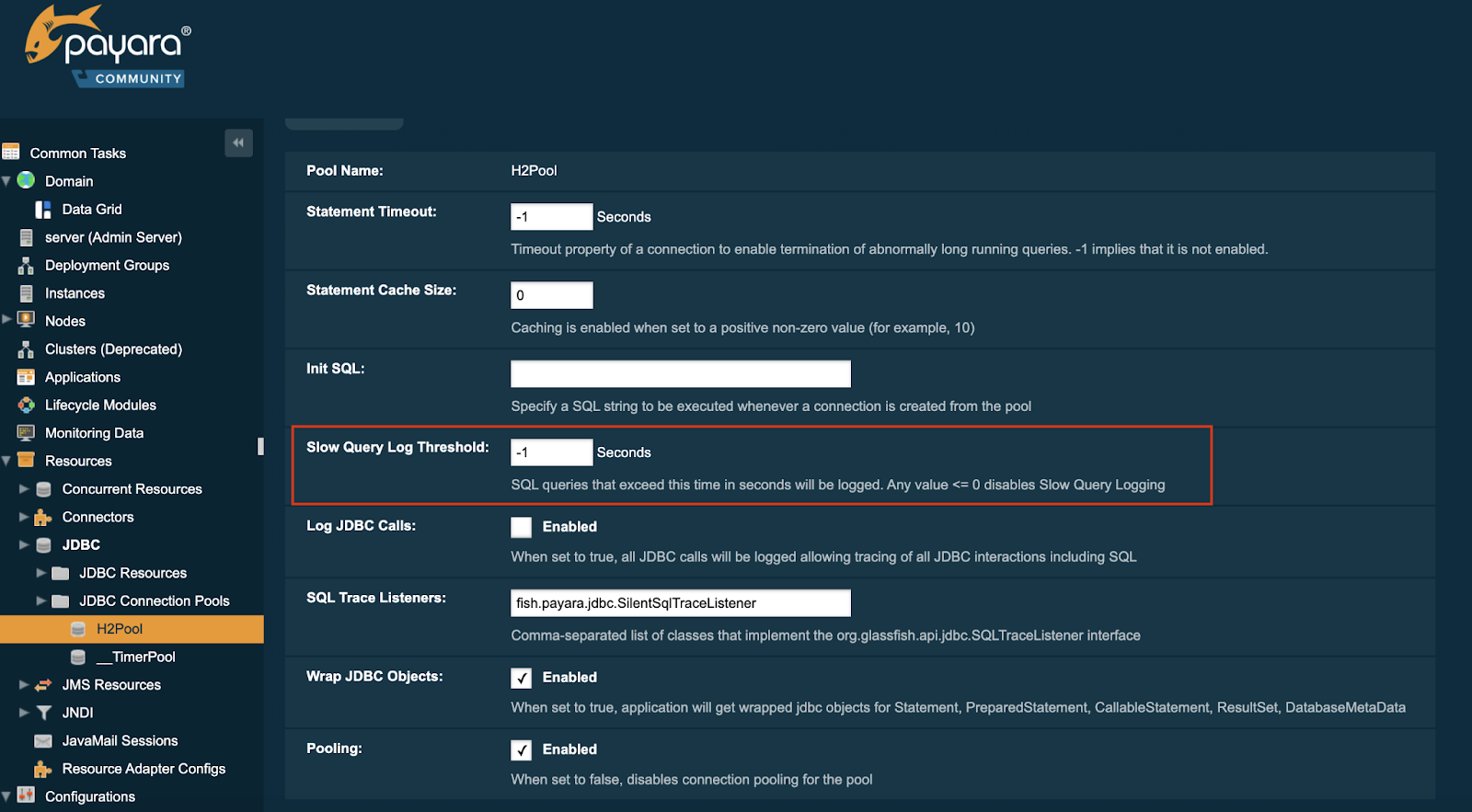
Slow SQL queries can silently undermine your application's efficiency and the overall user experience. These sluggish queries not only frustrate users with long load times, but they can also have significant costs:
Effortless Jakarta EE: Deploying Apps Directly from Your Java main() Method With Payara Micro
Published on 07 Mar 2024
by Luqman Saeed
Topics:
Payara Micro,
Java,
Jakarta EE
|
0 Comments
Jakarta EE offers a reliable foundation for enterprise-scale Java applications. Sometimes, however, the traditional deployment model can add a layer of complexity. Payara Micro addresses this challenge by providing a streamlined approach for managing your Jakarta EE deployments.
Customizing Payara Micro with Command-Line Options
Published on 26 Feb 2024
by Luqman Saeed
Topics:
Payara Micro
|
0 Comments

Payara Micro is a microservices optimised, cloud-first Jakarta EE runtime capable of executing WAR files directly from the command line, eliminating the need for a conventional application server setup. This efficient method, coupled with its versatility and extensive functionality, makes Payara Micro an ideal choice for simplifying your Jakarta EE development process. Its wide array of command-line options is designed to simplify configuration and management, further enhancing its appeal.