
Originally published on 20 Apr 2017
Last updated on 15 Feb 2018

Continuando con nuestra serie de introducción, este blog va a demostrar como configurar un cluster sencillo de dos instancias mediante Hazelcast.
See here for the original version in English language.
A diferencia de un entorno de desarrollo, donde un sólo servidor es necesario para servir de "prueba de concepto", en producción es normalmente necesario buscar la forma más confiable de hospedar tu aplicación a través de múltiples máquinas redundantes para garantizar la confiabilidad del servicio y permitir la escalabilidad en el futuro. Con Payara Server, es posible crear fácilmente y añadir instancias a clusters utilizando Hazelcast, haciendo muy fácil la configuración de una aplicación distribuida.
Requisitos
Para seguir este tutorial vas a necesitar:
- Una máquina Ubuntu con Payara Server ya instalado.
- Una máquina Ubuntu con JDK 8 instalada, instalaremos Payara Server más tarde.
- La aplicación de ejemplo rest-jcache de nuestro Repositorio de Ejemplos de Payara.
Nuestro primer paso es crear un nodo SSH. Para más detalles sobre qué es un nodo SSH, y porque vamos a usarlo aquí, lee este blog.
Configurar e instalar un nodo SSH con Payara Server
Una vez se han cumplido los requisitos, nuestro primer paso para crear un cluster será configurar nuestra segunda máquina Ubuntu ('computer2') con su propia instalación de Payara Server y la forma de comunicar con nuestra máquina Ubuntu original ('computer'). Como ambas máquinas funcionan con un sistema operativo GNU/Linux, y requerimos control total de la segunda máquina, vamos a crear un nodo SSH en la máquina computer2. Como parte de la creación del nodo, vamos a utilizar una característica muy útil de Payara Server, su habilidad para crear un archivo zip de sí mismo e instalarlo en un nodo remoto (lo que nos garantiza que ambas instalaciones son iguales y nos ahorra tiempo).
A alto nivel, los pasos para configurar computer2 son los siguientes:
- Configurar computer2 para que acepte tráfico SSH
- Crear un nuevo nodo SSH en el DAS
- Instalar Payara Server en el nodo SSH
Instalando un servidor SSH
Para recibir tráfico SSH, computer2 necesita tener un servidor SSH escuchando. La máquina virtual Ubuntu que voy a utilizar no tiene un servidor SSH instalado por defecto, por lo que vamos a instalar un servidor OpenSSH de los repositorios de Ubuntu con el siguiente comando:
sudp apt install openssh-server
Para versiones de Ubuntu anteriores a 16.04, el comando será 'apt-get install'
Después de instalar el servidor OpenSSH, este debería iniciarse automáticamente. Ejecutando 'netstat -lnt | grep 22' se debería mostrar que el puerto 22, el puerto por defecto para SSH, está ahora abierto y escuchando tráfic

Creando un nuevo nodo SSH en Payara Server
Ahora que tenemos SSH configurado en la segunda máquina Ubuntu podemos crear de forma segura el nuevo nodo. En la vista de Nodos de la consola de administración, clicar en el botón Nuevo 'New'.
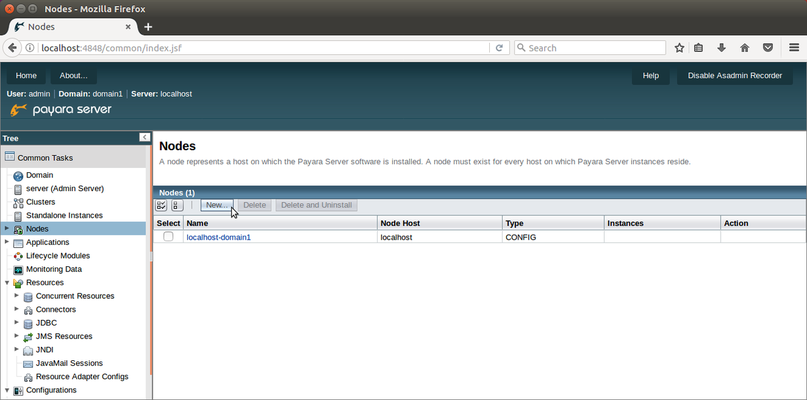
Ahora tenemos que rellenar las propiedades del nuevo nodo:
- Nombre: Proporciona a tu nodo un nombre único y descriptivo para ayudarte a identificarlo más tarde. Yo elijo computer2.
- Tipo: Selecciona SSH de la lista desplegable para que podamos configurar el acceso remoto
- Máquina del Nodo: Introducir la dirección IP de computer2.
- Installar Payara Server: Habilitarlo para que Payara Server se instale automáticamente en computer2. Payara Server creará un archivo zip de la instalación local y la copiara al nodo remoto. La ubicación de la instalación se puede modificar cambiando 'Directorio de Instalación' (que por defecto es la misma ruta en la que se encuentra en la máquina actual).
- Puerto SSH: Debe ser configurado al puerto SSH de la máquina computer2, que por defecto es 22.
- Nombre de usuario de SSH: Debe ser configurado con el nombre de usuario de la máquina computer2.
- Autenticación de usuario por SSH: Para este ejemplo, vamos a utilizar la autenticación por contraseña, pero con SSH también puedes utilizar un archivo de claves privadas o un alias a una contraseña almacenada en otro lugar.
- Contraseña de usuario SSH: Debe ser configurado con la contraseña de la máquina computer2.
Con el formulario completado, pulsa el botón OK. No te preocupes si ves un aviso diciendo "Se ha detectado un proceso de larga duración", hay una pequeña pausa mientras se realiza una copia de tu instalación de Payara Server y la instala en la segunda máquina Ubuntu.
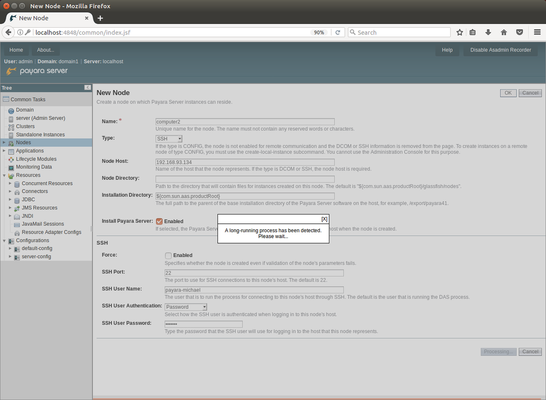
Una vez que la instalación de Payara Server ha sido transferida de forma segura, y el nodo ha sido creado, serás devuelto a la vista de Nodos.
Creando nuevas instancias locales
Con nuestro nodo remoto configurado, tenemos la base. Ahora vamos a configurar dos instancias, una en cada nodod, las cuales alojarán nuestra aplicación desplegada. Vamos a hacer el cluster con nuestras instancias utilizando Hazelcast en lugar del cluster basado en Shoal heredado, lo que quiere decir que vamos a necesitar crear dos instancias 'locales' que compartirán la misma configuración. Primero necesitaremos crear una nueva configuración que ambas van a referenciar para que, como en un cluster heredado, podamos hacer una sóla vez los cambios y afecten a ambas instancias.
Creando una nueva configuración
Para crear una nueva configuración para nuestro cluster Hazelcast, hacer clic en el elemento 'Configuraciones' en el menú del lateral izquierdo para ir a la página Configuraciones, en ella hacer clic en el botón 'Nuevo...' para crear una configuración nueva para nuestro cluster.
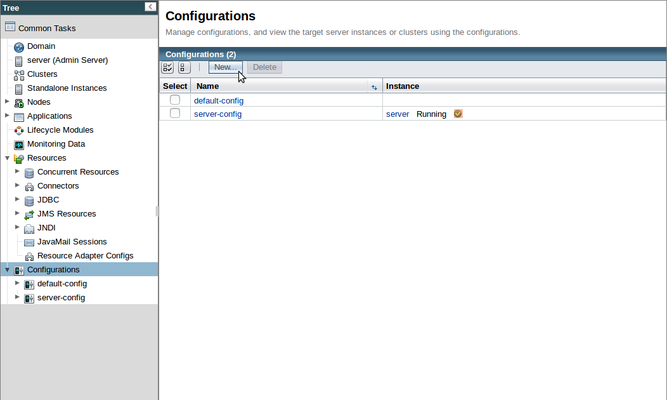
En toda instalación de Payara Server exisitirán dos configuraciónes:
- server-config es la configuración utilizada por el Servidor de Administración (llamado 'server'). Los cambios realizados aquí afectarán al DAS.
- default-cofig es proporcionada para ser utilizada como una plantilla, a partir de la cual se puedan crear otras configuraciones, Se puede utilizar directamente, lo cual NO es aconsejable.
Como no queremos añadir modificaciones accidentalmente en la configuración del DAS, vamos a copiar la default-config y renombrarla como cluster-config.
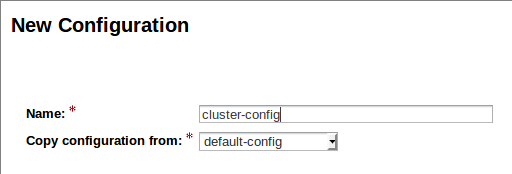
Aceptar la configuración por defecto seleccionada y guardar la nueva configuración.
Creando una instancia local
Ahora, vamos a crear instancias que utilizaran nuestra configuración. Para crear una instancia en la máquina local, clicar en 'Nuevo' en la página Instancias del Servidor Locales,
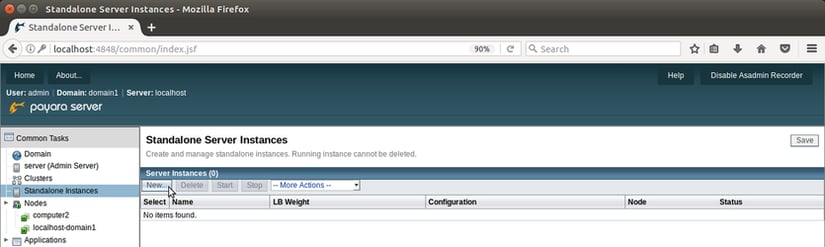
On the New Standalone Server Instance page, create the instance as shown below:
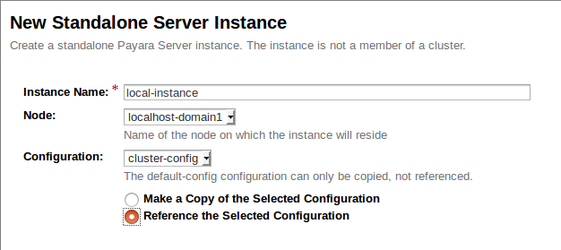
- Nombre de la Instancia: He llamado mi instancia 'local-instance' para que esté claro que es la instancia ubicada localmente en la máquina que contiene el DAS.
- Nodo: El nodo localhost-domain1 es el nodo por defecto que está ubicado localmente en la máquina que contiene el DAS.
- Configuración: Aquí utilizaremos la configuración creada anteriormente, cluster-config, por lo que debemos estar seguros de referenciarla.
Pulsar 'OK' para terminar de crear nuestra primera instancia.
Creando una instancia remota
Podemos repetir el mismo proceso anterior para crear una instancia en el nodo remoto simplemente referenciando a la máquina remota de la siguiente manera:
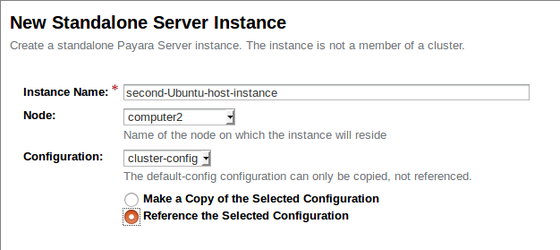
Pulsar 'OK' para crear nuestra segunda y última instancia y volver a la página de Instancias Locales. Ahora deberías tener dos instancias marcadas como 'Detenida'. Selecciona ambas utilizando las cajas de selección a su izquierda e inícialas.
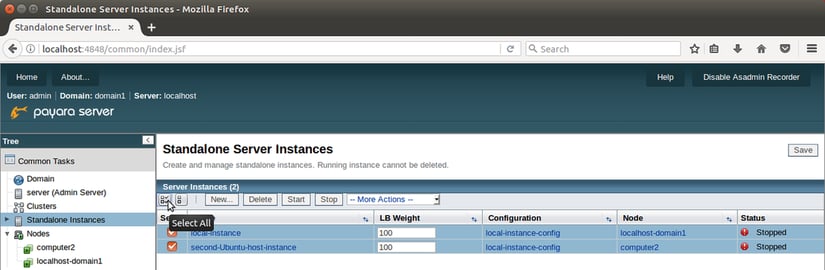
Habilitando Hazelcat
Con nuestras instancias iniciadas y referenciando a la misma configuración, cualquier cambio en cluster-config será aplicado en ambas instancias, así como cualquier otra instancia que creemos referenciando a la configuración cluster-config.
Para habilitar Hazelcast en cluster-config, navegar hacia abajo en el árbol del menú 'Configuraciones' y expandir 'cluster-config'.
Hacer clic en la pestaña Hazelcast, marcar la caja de selección 'Habilitado' y guardar los cambios.
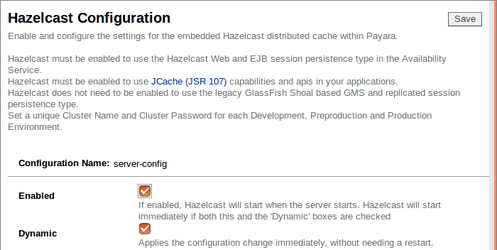
Podemos dejar el resto de las configuraciones en los valores por defecto, aunque esto depende de que la comunicación de multidifusión UDP sea posible en nuestra red. Si tienes algún problema con el descubrimiento automático de Hazelcast, la multidifusión UDP es una de las cosas a verificar.
Ver los miembros de un Cluster Hazelcast
Si has habilitado Hazelcast con la opción Dinámico habilitado, deberías ver los mensajes de registro mostrando la inicialización de Hazelcast y los dos miembros descubriéndose unos a otros. Para ver tu cluster Hazelcast, selecciona "Dominio" en el árbol de páginas, y selecciona la pestaña "Hazelcast" y finalmente la subpestaña "Miembros del Cluster" para ver la pestaña Miembros del Cluster Hazelcast. Aquí puedes ver todos los miembros del cluster, junto con las aplicaciones desplegadas en ellos.
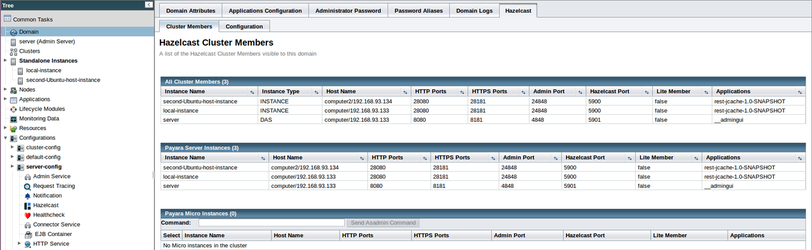
Ahora tenemos nuestras instancias configuradas, y Hazelcast indica que están enlazadas correctamente en cluster, los que significa que podemos probarlo!
Demostrando la replicación de caché
Preparando la aplicación de ejemplo de Payara
El repositorio de Ejemplos de Payara en Github está repleto de proyectos que demuestran características específicas disponibles para Payara Server. Nosotros utilizaremos la aplicación rest-jcache para demostrar como Hazelcast distribuye fácilmente los datos, pero primero, tenemos que descargarla y prepararla.
-
Para descargar y construir el repositorio necesitarás Git y Maven instalados. Ambos están disponibles en los repositorios de Ubuntu y se pueden instalar con el siguiente comando:
sudo apt install git maven -
Clonar el repositorio de Ejemplos de Payara en la primera máquina Ubuntu con el siguiente comando:
git clone https://github.com/Payara/Payara-Examples - Vamos a construir el ejemplo rest-jcache, por lo que una vez descargado el repositorio, cambiar al directorio "<payara_examples_directory>/rest-examples/rest-jcache". Una vez aquí, puedes ejecutar el comando "mvn clean install" para utilizar Maven para construir el projecto.
Maven descargará automáticamente las dependencias del proyecto y lo construirá: la aplicación web compilada será almacenada como un fichero WAR dentro del directorio target:

Ahora que tenemos nuestra aplicación de prueba preparada, podemos desplegarla!
Desplegando la aplicación de ejemplo de Payara
Para probar la habilidad de caché distribuida de nuestro cluster, desplegaremos la aplicación en toda las instancias del cluster y añadiremos algunos datos para demostrar como podemos modificar los datos dentro de todo el cluster al mismo tiempo editando los valores en la caché de una sola instancia local.
Primero, seleccionar la página "Aplicaciones" en el árbol de páginas y hacer clic en "Desplegar...".
Después, subir la aplicación construida utilizando el botón "Buscar..., asegurándote de que añades ambas instancias del cluster en el listado de "Destinos Seleccionados":
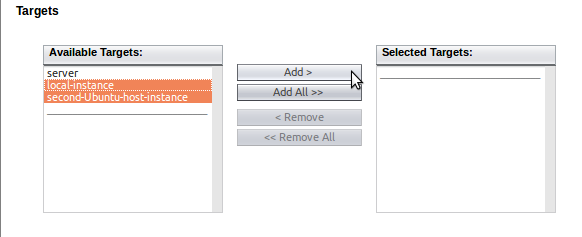
Payara Server se encargará de distribuir la aplicación a las instancias que hayamos seleccionado como destinos.
Probando el cluster con la aplicación de ejemplo de Payara
La aplicación rest-jcache utiliza las anotaciones de la API JCache en los métodos REST JAX-RS y escucha en el extremo de la "caché". Todas las peticiones GET, PUT y DELETE están soportadas:
- GET
El método getJSON() tiene la anotación @GET, por lo que será llamado con cada petición GET para "cachear" el recurso. La anotación @CacheResult es una anotación de JCache que realiza una búsqueda en la memoria caché nombrada y devuelve el valor almacenado en la cache de existir uno previamente, de lo contrario ejecuta el cuerpo del método. Si el valor no existe, el cuerpo del método se ejecutará y la cadena de texto "helloworld" será devuelta. En una aplicación real, esto podría ser una búsqueda en la base de datos. - PUT
El método putJSON() tiene la anotación @PUT, por lo que puede ser ejecutado con una petición PUT HTTP. La anotación @CachePut es utilizada junto con las anotaciones @CacheKey y @CacheValue en la declaración del método para poner el valor proporcionado en la caché nombrada. Hemos utilizado el mismo nombre de caché que en el método GET, por lo que cualquier clave que actualicemos con una petición PUT, se verá reflejada en una petición GET posterior. - DELETE
De la misma manera que en con los otros métodos, hemos utilizado una anotación JAX-RS (@DELETE) junto con la anotación JCache (@CacheRemove) para que cuando se reciba una petición DELETE HTTP, el valor con el que la clave proporcionada coincida será borrado de la caché.
Primero demostraremos como la secunda máquina Ubuntu tiene el valor por defecto "helloworld" para, editando el valor almacenado dentro de la primera máquina Ubuntu, mostrar cómo Hazelcast hará disponible automáticamente la entrada de caché para todos los miembros del cluster.
- Recuperando el valor por defecto para la clave "payara"
Nuestros datos están almacenados dentro de la aplicación en un formato JSON como pares de clave-valor. Recuperar una clave cuyo valor no existe en la cache retornara el valor por defecto "helloworld", el cual recibiremos en la segunda instancia Ubuntu cuando enviemos el siguiente comando desde nuestra primera instancia Ubuntu:
curl "http://<IP_Remota>:<Puerto_de_Instancia_Remota>/rest-jcache-1.0-SNAPSHOT/webresources/cache?key=payara"

Como puedes ver, actualmente no hay valor almacenado para "payara" por lo que obtenemos el valor por defecto en respuesta desde la segunda instancia.
2. Añadir un nuevo valor para la clave "payara" en la instancia local
Podemos añadir un valor para la clave "payara" desde nuestra primera instancia con el siguiente comando:
curl -H "Accept: application/json" -H "Content-Type: application/json" -X PUT -d "badassfish" "http://<IP_Local>:<Puerto_de_Instancia_Local>/rest-jcache-1.0-SNAPSHOT/webresources/cache?key=payara"
 Gracias a la cache de Hazelcast, este par clave-valor actualizado será distribuido inmediatamente a todas las instancias de nuestro cluster.
Gracias a la cache de Hazelcast, este par clave-valor actualizado será distribuido inmediatamente a todas las instancias de nuestro cluster.
3. Recupera el nuevo valor de la instancia remota
Seremos capaces de ver este nuevo valor inmediatamente cuando volvamos a ejecutar nuestro comando inicial en la segunda instancia:
curl "http://<IP_Remota>:<Puerto_de_Instancia_Remota>/rest-jcache-1.0-SNAPSHOT/webresources/cache?key=payara"

Y aquí lo tenemos, un cluster funcionando con Payara Server, potenciado por Hazelcast! Ahora tenemos nuestro cluster listo, podemos empezar a desplegar nuestras aplicaciones y aprovechando al máximo nuestra nueva escalabilidad, así como configurando nuestro cluster para realizar balanceo de carga y manejar apropiadamente las sesiones que se tratarán en próximos blogs.
See here for the original version in English language.

Related Posts
Payara Server's High Availability Architecture: A Quick Technical Overview
Published on 05 Jun 2024
by Luqman Saeed
2 Comments

Introduction
In today's business world, competition is fierce and relentless. As a result, maximizing uptime while reducing downtime and its expenses is a top priority. In particular, users now expect applications to deliver consistent ...
Continuous Integration and Continuous Deployment for Jakarta EE Applications Made Easy
Published on 25 Mar 2024
by Luqman Saeed
1 Comment
Continuous Integration and Continuous Deployment (CI/CD) activities are designed to convey your Jakarta EE applications to end users. Thanks to the unique flexibility of Jakarta EE, multiple CI/CD options are available to software developers. ...