
Posts from Patrik Duditš

How to Make Multi-Cloud Work
Published on 19 Jun 2025
by Patrik Duditš
Topics:
Cloud,
Developer,
Payara Cloud
|
0 Comments

Multi-cloud developments can offer real operational advantages. However, careful and strategic planning is key to maximize the gains. In fact, without clear operating models or setups, teams can experience costly missteps and cloud spent wastage.
At Payara Services, we work closely with organizations deploying mission-critical enterprise Java applications across hybrid and multi-cloud environments. As a result, our engineering team has been actively engaged in helping companies succeed in their multi-cloud strategies, and we know first-hand what works best as well as common pitfalls. In this blog post, we look at what multi-cloud is and share key insights and tips to optimize your multi-cloud projects.
You Might Not Need Kubernetes. Or Containers.
Published on 23 Jan 2024
by Patrik Duditš
Topics:
Cloud,
Kubernetes
|
0 Comments
.jpg?width=500&name=Payara%20Cloud%20Maze-01%20(1).jpg)
Kubernetes is a topic that is frequently discussed in the development community, especially as the IT landscape increasingly shifts towards cloud and microservices. However, it’s crucial to evaluate whether it is genuinely indispensable for your environment or just another case of the next 'new and shiny' object capturing attention without substantial benefits. In this blog, we’ll delve into the reasons why Kubernetes might sometimes fall victim to the hype and explore whether it is the right fit for all scenarios.
Deploying to Payara Cloud from a GitHub Action Workflow
Published on 05 Sep 2022
by Patrik Duditš
Topics:
CLI,
Cloud,
Cloud-native,
Payara Cloud,
Getting Started with Payara Cloud
|
0 Comments
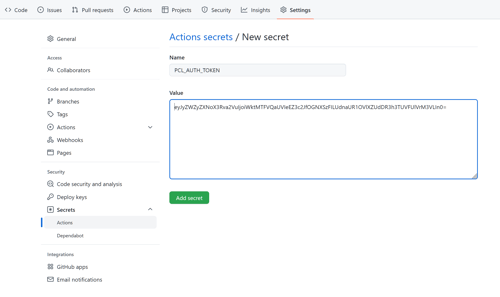
Payara Cloud provides an easy-to-use user interface to allow your application to run in a managed cloud environment. While this is very convenient for configuration and troubleshooting work, integration in continuous deployment pipelines calls for something else. Our answer is deploying to Payara Cloud using a GitHub Action Workflow and Payara Cloud Command Line (PCL).
Prevent Classloading-Related Issues with Payara BOM
Published on 25 Jun 2020
by Patrik Duditš
Topics:
Payara Server 5,
Payara Platform 5,
BOM
|
3 Comments

The runtime image of Payara Server consists of over 400 modules. Half of these do not come directly from the Payara codebase, but are various third-party APIs, their implementations and helper libraries. How do you choose the correct versions of your application's libraries so they are not in conflict with the ones in the server runtime?
Warming Up Payara Micro Container Images in 5.201
Published on 05 Mar 2020
by Patrik Duditš
Topics:
Payara Micro,
New Releases
|
2 Comments
Payara Micro 5.201 adds two command line options that make preparation of container images easier, as well as enable class data sharing on HotSpot Java Virtual Machine.
Faster Payara Micro Startup Times with OpenJ9
Published on 04 Feb 2020
by Patrik Duditš
Topics:
Payara Micro
|
3 Comments
One of the performance metrics that are frequently compared by developers are startup times. Payara Server is designed to be manageable at runtime, with a central management server (DAS - domain administration server) and multiple instances, and as such is not optimized for extremely fast startup time. Payara Micro on the other hand, is optimized to run predefined workloads with a stable configuration at runtime, and is therefore a better fit for for comparing start up time metrics.
In this blog, let's take a look at how you can configure Payara Micro for fast startup time by utilizing the class data sharing feature of Eclipse OpenJ9.
The Road to Jakarta EE Compatibility
Published on 11 Dec 2019
by Patrik Duditš
Topics:
JakartaEE
|
4 Comments
Payara Platform 5.194 was released recently, and just like the previous release, it is a certified Jakarta EE implementation. The request for certification can be seen on Jakarta EE platform project issue tracker.
Payara Server is Jakarta EE 8 Compatible!
Published on 09 Oct 2019
by Patrik Duditš
Topics:
JakartaEE,
news and events,
New Releases
|
0 Comments

We are very happy to report that we've successfully passed all of nearly 50,000 test suites of Jakarta EE 8 TCK, and Payara Server 5.193.1 is Jakarta EE 8 Full Profile compatible!
Log directly to Logstash from Payara Server
Published on 30 Nov 2017
by Patrik Duditš
Topics:
Java EE,
JVM
|
0 Comments

(Guest blog)
When running multiple instances of an application server, it is quite hard to see correlations between events. One of the best tools to enable that is the ELK stack - Elasticsearch for building fulltext index of the log entries, Logstash for managing the inflow the events, and Kibana as a user interface on top of that.
Solutions for Payara Server exist, that use better parseable log format which can be then processed by Logstash Filebeat in order to have these log entries processed by a remote Logstash server.
In our project, we chose a different path — we replaced all logging in the server and our applications with Logback, and make use of the logback-logstash-appender to push the events directly to Logstash over a TCP socket. The appender uses LMAX disruptor internally to push the logs, so the processes does not block the application flow. This article will show you how to have this configured for your project as well.