
Originally published on 15 Jun 2015
Last updated on 27 Mar 2019

Payara Micro is our new embedded distribution that was part of our latest release.
As Steve describes in his introductory blog, Payara Micro allows you to run war files from the command line, without any application server installation, in our new way of running Java EE applications. In this blog, I’ll demonstrate the automatic clustering capabilities of Payara Micro, made possible through the integration of Hazelcast.As shown in the introductory blog, you can start a Payara Micro instance and deploy a file with a single command:
java -jar payara-micro.jar --deploy test.war
This command can be extended to also configure the Payara Micro instance. To see a full list of the options, you can run Payara Micro with the --help option:
java -jar payara-micro.jar --help
Which will list the following:
--noCluster Disables clustering--port sets the http port--sslPort sets the https port number--mcAddress sets the cluster multicast group--mcPort sets the cluster multicast port--startPort sets the cluster start port number--name sets the instance name--rootDir Sets the root configuration directory and saves the configuration across restarts--deploymentDir if set to a valid directory all war files in this directory will be deployed--deploy specifies a war file to deploy--domainConfig overrides the complete server configuration with an alternative domain.xml file--minHttpThreads the minimum number of threads in the HTTP thread pool--maxHttpThreads the maximum number of threads in the HTTP thread pool--help Shows this message and exits
Two particularly useful options are the --port and --mcAddress options.
The first you’ll need to use to avoid port conflicts (particularly if you intend to run two or more instances on the same machine), and the second is useful if you intend to cluster two or more instances on separate machines.To demonstrate the clustering, I’ll deploy an application called clusterjsp.war, which just displays information about the instance running it and the session ID. It also allows the user to store some session data. Start two Payara Micro instances, and deploy your application on both.For this example, I’ll start two instances on the same machine (you’ll need two terminal windows):
java -jar payara-micro.jar --deploy clusterjsp.warjava –jar payara-micro.jar --deploy clusterjsp.war --port 2468
Note that for the second instance I started it on a different HTTP port with the --port option, to prevent a port conflict.In the log output of the Micro instances, you should see them automatically cluster together. You’ll know they’ve clustered if you see this message:
Members [2] {
Member [192.168.174.130]:5900 this
Member [192.168.174.130]:5901
If they don’t cluster together, make sure your firewall is configured correctly.And that should be it! Your application will now be clustered between both Payara Micro instances, with the session data replicated between them. If you want to try this out, you can download the clusterjsp.war file from here.To demonstrate:
Add some session data on one instance…
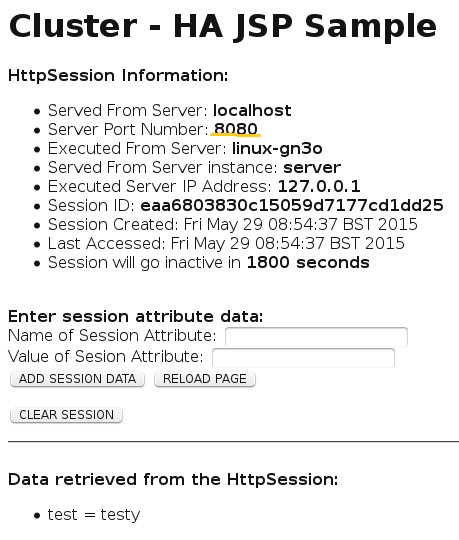
Then load the second, and see that the session data and ID have replicated successfully.
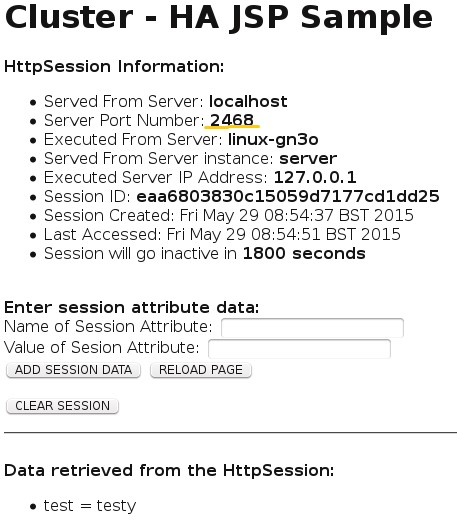
Give Payara Micro a go yourself, and let us know what you think!
Related Posts
The Payara Monthly Catch - August 2025
Published on 02 Sep 2025
by Dominika Tasarz
0 Comments

Welcome aboard the August 2025 issue of The Payara Monthly Catch! With summer in full swing, things may have felt a little more quiet across the Java world - but certainly not less interesting! We hope you managed to get some rest and recharge, ...
Conquering Kubernetes Complexity: Why Java Developers Need More Than Just Containers
Published on 08 Aug 2025
by Chiara Civardi
0 Comments

Kubernetes, also known as K8s has become the de facto platform for orchestrating modern microservices architectures, promising resilience, scalability and faster deployment pipelines for Java applications. But for many developers, that promise ...