
Originally published on 05 Jul 2016
Last updated on 19 Jul 2016

Application server clustering provides a means to make application infrastructure more robust and perform better. However, it is often very inflexible and even a small change in the cluster topology can involve serious maintenance costs. Payara Server supports a new way of clustering based on Hazelcast, which brings much more flexibility, decreases maintenance costs and adds the benefit of JCache support out of the box.
This new method of clustering elegantly fits the needs of modern cloud deployments. It makes it easy to scale the infrastructure for our applications dynamically, without any complex configuration or downtime. Even for on-premise deployments, it is still much more convenient and flexible, compared to the traditional clustering methods.
But we may be facing other problems. What if we need:
- to increase the size and robustness of the distributed memory?
- to distribute the shared memory non-uniformly?
- to create high throughput nodes?
- to deploy a micro service besides our main application?
All of the above problems have a solution when using Payara Server clustering based on Hazelcast:
- Additional empty nodes can be added just to provide additional replicas
- Memory distribution can be balanced by setting some nodes as lite members which do not keep the data
- Nodes configured as lite cluster members have smaller heap size and subsequently they spend less time in garbage collection, while still having access to the distributed memory
- Additional micro services can be deployed easily using Payara Microruntime, while still enjoying benefits of the cluster
We will explore various clustering topologies to illustrate how to take advantage of the flexibility that Payara Server provides.
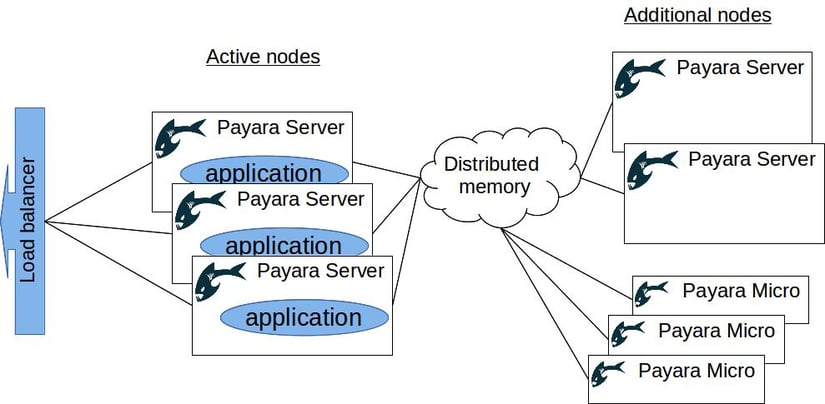
Adding nodes to scale the distributed memory
Once we have our clustered environment up and running, we can easily add more nodes to the cluster just by running additional standalone servers. Even without any applications deployed, these extra instances would serve as additional members of the cluster. This brings some more benefits:
- Additional instances share the burden of distributed memory, allowing a decrease in the memory consumed by individual members
- The number of replicas increases, making the shared memory more robust and tolerant to failures
With this simple approach, we can scale some aspects of our environment with very little effort. On top of that, this approach is completely reusable in any scenario. Therefore it is easy to build a common Docker container, or even take the one provided by Payara, and use it to start new cluster instances.
The same can be achieved by running Payara Micro instances. Payara Micro provides the same clustering features as Payara Server, with additional simplicity. It is possible to run this small runtime from the command line with additional configuration, and even make it automatically bind to a free HTTP port to avoid collisions.
Introducing JCache to avoid unnecessary database access
Using Hazelcast clustering adds the benefit of distributed cache, which is also available through JCache API. This is a common caching API defined in the JSR-107 specification. Any application can make use of it to cache data retrieved from a database and other external sources.
However, we may extend the original purpose of this cache to provide a distributed in-memory data grid. JCache API provides options to create an eternal cache, which persists data as long as the cluster is running, and to store and retrieve data from the cache. Using the previous method, it is possible to scale the data grid to fit all the necessary data and to reduce database hits to a minimum. And it is still possible to persist the data in the cache into the database using custom cache entry listeners.
Focused on throughput and performance
Storing data into the distributed cache has impact on the size of the JVM heap for each member of the cluster. Once the deployed applications start to make use of distributed cache extensively, the requirements on the heap size will grow. This may negatively impact application performance. Moreover, it is hard to predict and manage the maximum heap size in such a situation, especially if the applications themselves require a big portion of the heap for regular processing.
In the case when any negative impact is undesirable, Payara Server enables turning certain nodes in the cluster into lite members. Such nodes do not provide any storage or computation to the cluster, while preserving all the benefits of the cluster. This opens another dimension of flexibility, enabling scaling the performance independently from scaling the available memory. Lite members connect to the cluster in the same way as usual members, but they don't provide any resources to the cluster and have all the computing power and the heap space for themselves. This has the effect of decreased heap size, less time spent in garbage collection and therefore more predictable behavior.
Once we choose to use lite cluster members to improve the throughput of some nodes, it also makes sense to choose an appropriate strategy to tune the JVM. Nodes that target high throughput and smaller heaps will most probably require different JVM configuration to nodes where the expected heap is much higher. We could go even further and run the throughput nodes on a 32bit JVM, if 2Gb of heap space is enough. Using a 32bit JVM reportedly decreases memory consumption in some cases, which could have dramatic impact on performance.
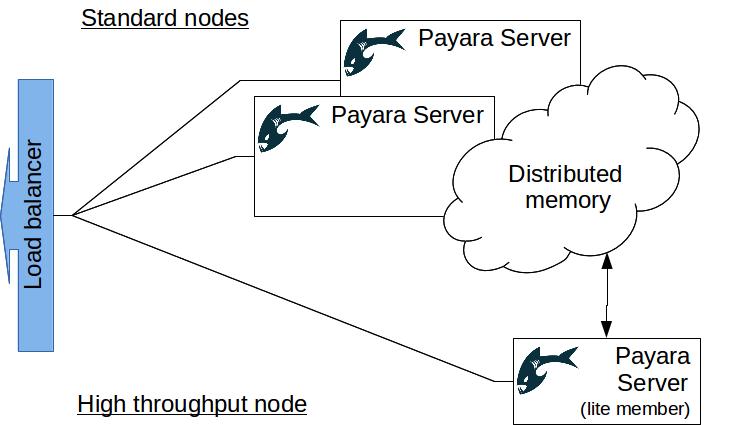
When using lite members, it is important that enough full cluster members are present in the cluster to retain its reliability. If performance and unpredictable heap sizes are an issue, the Payara Scales add-on to Payara Server provides Hazelcast Enterprise's High-Density Memory Store, which off-loads the distributed data out of the heap space. Among other enterprise features, it also enables the joining of instances from multiple remote data centers into a single cluster, making it possible to bring the cluster closer to the clients to improve response times.
Breaking the monolith to microservices
With Payara Server, it is already very easy to deploy multiple applications into the cluster in various topologies, and scale them independently. However, the introduction of microservice patterns into the architecture can allow for even more flexibility and smaller runtimes. With Payara Server, we can achieve both by introducing Payara Micro into our cluster. Doing this, we can not only build a suitable infrastructure to support microservices, but also schedule a maintainable step-by-step process to migrate any monolithic architecture to the desired microservice architecture.
Since version 162, Payara Micro can join an existing cluster of Payara servers. This solution combines the power of both architectural approaches. New microservices can be deployed gradually as a growing number of Payara Micro instances, while existing applications are running on the same Payara Server instances they were running before. With this approach, it is easy to focus on development of new microservices, without the need to refactor much of already working code.
Payara Micro is designed for microservice architectures. It is a small runtime providing a convenient subset of Java EE API and the following features:
- Can be executed simply from command line or in a Docker container
- Has small memory footprint
- Supports API for REST services via JAX-RS
- Supports distributed messaging based on CDI events, instead of heavy-weight JMS messaging
- Provides option to bind to free HTTP ports automatically
- Provides API to access Payara Micro runtime directly from within deployed applications, no JNDI necessary
What's even more important, Payara Micro supports many of the enterprise features of Payara Server. This makes it easier to break down current monolithic applications into microservices, and reuse most of the code and expertise. Some of the features Payara Micro and Payara Server share are:
- Ability to join Payara cluster
- Ability to run as Lite cluster member
- Distributed cache via JCache
- Health-check service to monitor resource utilisation and detect stuck threads
- Support of Java EE APIs (web profile)
On top of that, it is worth mentioning that Payara Micro also provides the same administration commands as Payara Server. However, they are not exposed through a remote interface - instead, they are available through the Payara Micro API, accessible by deployed applications.
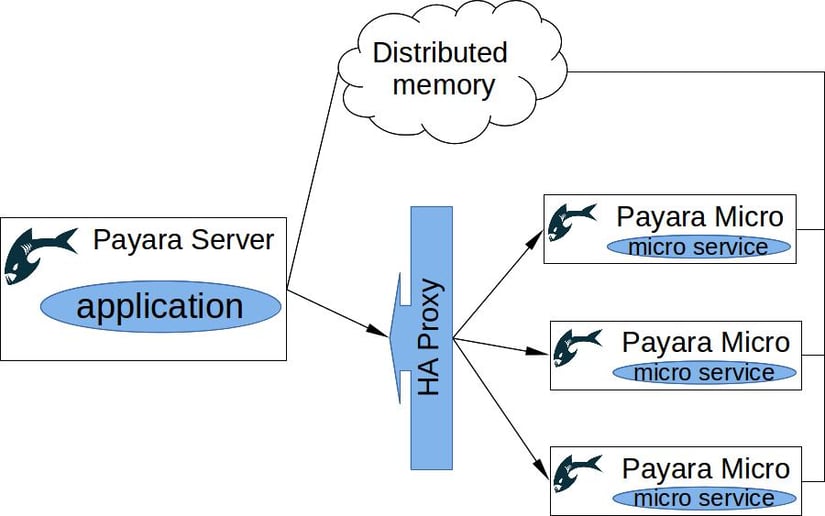
The best approach to breaking a monolith is to separate pieces of functionality into microservices one at a time. Such microservices can be deployed with Payara Micro runtime and scaled behind a high-availability proxy, such as HAProxy orNginx. These instances can also make use of the shared distributed memory in the cluster. Individual Payara Micro instances can even take advantage of the distributed CDI event bus for synchronization and communication.
Flexibility is the essence
Payara Server clustering has evolved into a flexible, elastic way of deploying highly available applications in various architectures. With the addition of Payara Micro, a cluster can be turned into a swarm of many small, but very agile and powerful instances.
With this flexibility, it is easy to deploy and scale the applications in any environment, be it an infrastructure based on Docker containers, any sort of cloud, or a range of interconnected devices in the IoT world.
Find out more about Payara Server's scaling & clustering capabilities.
Related Posts
The Payara Monthly Catch - August 2025
Published on 02 Sep 2025
by Dominika Tasarz
0 Comments

Welcome aboard the August 2025 issue of The Payara Monthly Catch! With summer in full swing, things may have felt a little more quiet across the Java world - but certainly not less interesting! We hope you managed to get some rest and recharge, ...
Conquering Kubernetes Complexity: Why Java Developers Need More Than Just Containers
Published on 08 Aug 2025
by Chiara Civardi
0 Comments

Kubernetes, also known as K8s has become the de facto platform for orchestrating modern microservices architectures, promising resilience, scalability and faster deployment pipelines for Java applications. But for many developers, that promise ...