
Originally published on 04 Nov 2019
Last updated on 04 Nov 2019

In a recent article we showed you how to configure pools and resources in Payara Server. One question from the comments on that blog was:
"How you guys manage connection pools for databases that are stored on the same database server?"
Maybe it looks like a trivial question, but if you develop larger applications using more databases, it can lead to very complicated problems with scalability, separation and overall data organization. So, let's start slowly...
Application Descriptor or Annotation
In the simplest case, you have a static database per application, which can be configured in Application Descriptor and even in Annotation, because they don't change between application versions. Both the descriptor element and the annotation are repeatable, so you can create pool definitions for all your databases and then add some business logic selecting a source by some criteria.
Advantage
- Everything in one place - in the application
Disadvantages
- Reconfiguration means new application version (or hacking)
- Limited flexibility
Example
@DataSourceDefinition(name = JdbcDsName.JDBC_DS_1, //className = "com.mysql.cj.jdbc.MysqlDataSource", //serverName = "tc-mysql", //portNumber = 3306, //user = "mysql", //password = "mysqlpassword", //databaseName = "testdb", //properties = { //"useSSL=false", "useInformationSchema=true", "nullCatalogMeansCurrent=true", "nullNamePatternMatchesAll=false" //})@DataSourceDefinition(name = JdbcDsName.JDBC_DS_2, //className = "com.mysql.cj.jdbc.MysqlDataSource", //serverName = "tc-mysql", //portNumber = 3306, //user = "mysql", //password = "mysqlpassword", //databaseName = "testdb", //properties = { //"useSSL=false", "useInformationSchema=true", "nullCatalogMeansCurrent=true", "nullNamePatternMatchesAll=false" //})@Path("ds")@Stateless@TransactionAttribute(TransactionAttributeType.NOT_SUPPORTED)public class DataSourceDefinitionBean {
Domain Configuration
Usually you develop an application which uses several external databases, maybe you even have some preproduction environment with your own database server, so configuring it in the Application Descriptor or Annotations is not what you would like to use.
Then it is logical to configure resources and pools in domain configuration using it's admin user interface or asadmin commands. Configuring several pools with the only difference in it's name is more simple with asadmin, you can create simple script:
#!/bin/bashset -eset -o pipefaildatabases="ANIMALS,PLANTS,VIRUSES"passwordfile="./passwordfile.txt"Field_Separator=$IFSIFS=','# don't forget to install the JDBC driver!# asadmin --user admin --passwordfile "${passwordfile}" add-library "./mysql-connector-java-8.0.18.jar";for dbName in ${databases};doecho "Creating pool and resource to ${dbName}";poolName="pool-${dbName}";dsName="jdbc/ds_${dbName}";asadmin --user admin --passwordfile "${passwordfile}" create-jdbc-connection-pool --ping --restype javax.sql.DataSource --datasourceclassname com.mysql.cj.jdbc.MysqlDataSource --steadypoolsize 5 --maxpoolsize 20 --validationmethod auto-commit --property user=mysql:password=mysqlpassword:DatabaseName=${dbName}:ServerName=tc-mysql:port=3306:useSSL=false:zeroDateTimeBehavior=CONVERT_TO_NULL:useUnicode=true:serverTimezone=UTC:characterEncoding=UTF-8:useInformationSchema=true:nullCatalogMeansCurrent=true:nullNamePatternMatchesAll=false "${poolName}";asadmin --user admin --passwordfile "${passwordfile}" create-jdbc-resource --connectionpoolid "${poolName}" "${dsName}";doneIFS=$Field_Separator
Note that pool names don't have any meaning for the application, they are important only to connect the data source with the right database pool. So in our case it is good to name both pools and resources by the databases.
Advantages
- JDBC pools and resources can be shared by applications running on the same instance
- Configuration changes may be done by trained administrator, not only by developers
- Less code in application - you need only datasource name
Disadvantages
- Concurrent access from applications
- Improper implementation of one application can influence another application on the same instance
Deployment Groups
Deployment groups can offer more flexibility for configuration of application infrastructure, because you can use variables to configure limits and even names on the same definition of the database pool - and define those variables for individual instance or deployment group.
Advantages
- Compromise, less configuration, grouping instances with same configuration blocks but still using same server configuration
- Configuration is complicated but still on one place without duplicities
Disadvantages
- It may be complicated with many instances
Example
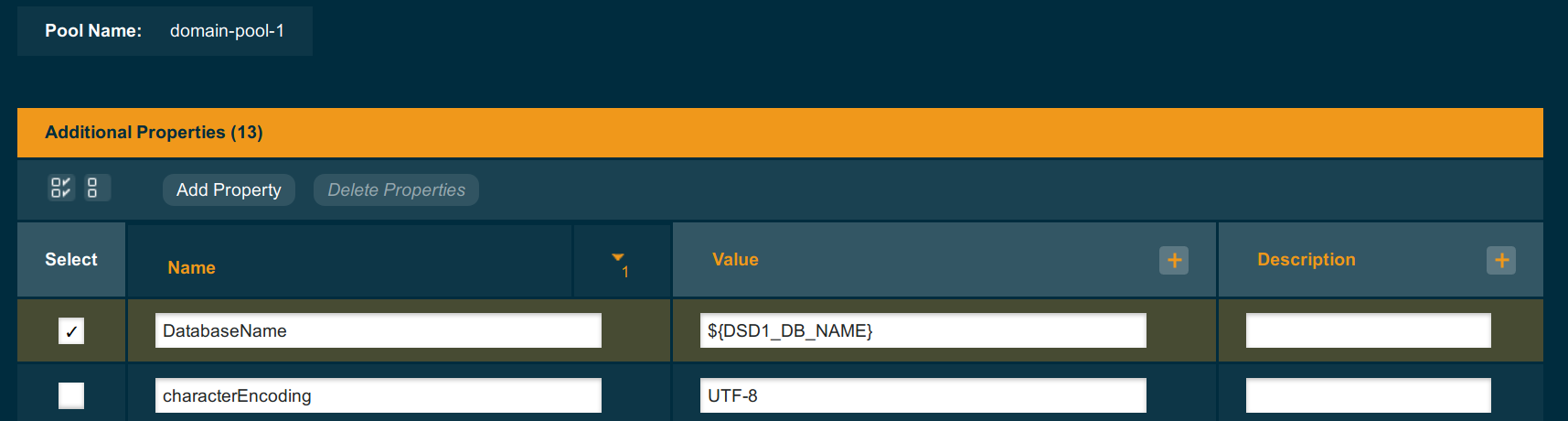
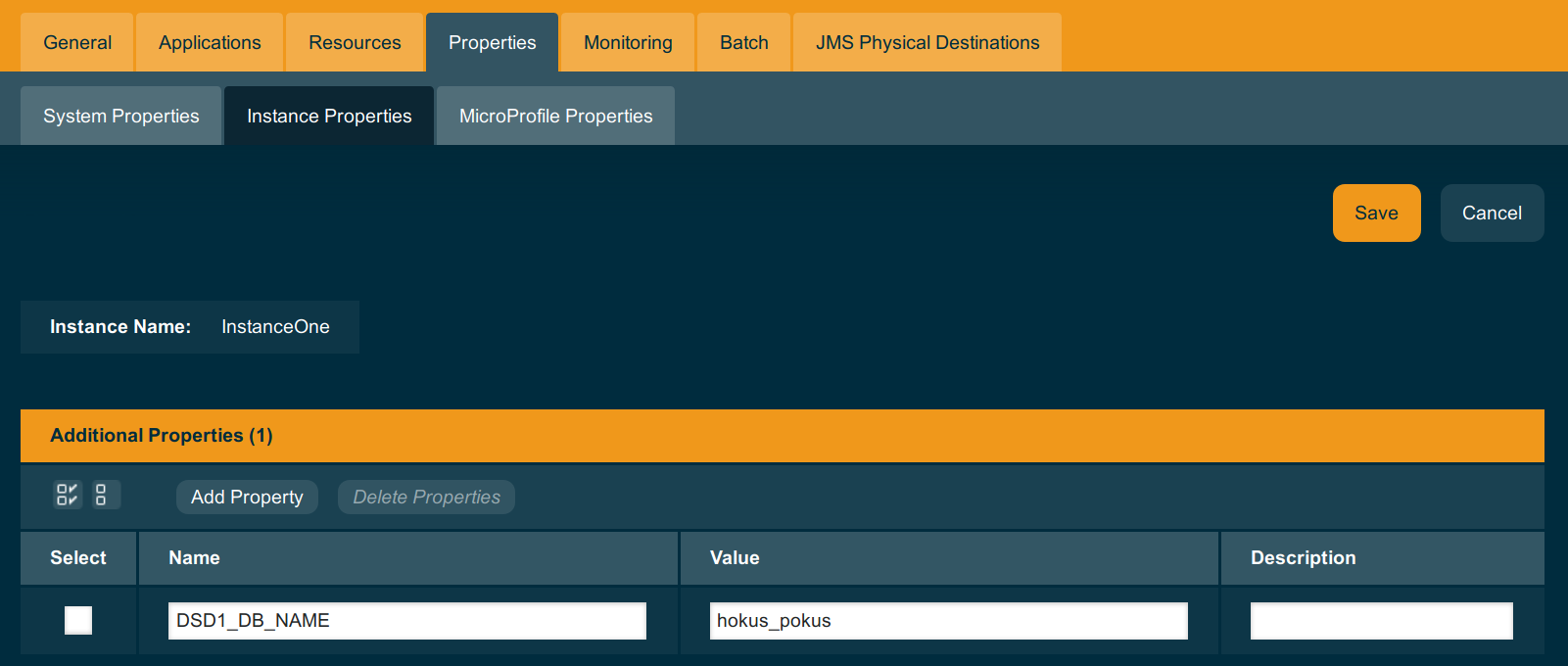
Thousands of Databases
Well, here comes the problem - if your application uses thousands of databases, I'm pretty sure you don't want to create any of the previous connection pools for each of them.
I would also expect that selection of the right database instance depends on some logic - business logic, so it would be somewhere in the application.
But there is also another option - some database providers implemented their own solutions even for this case, but these solutions differ in implementation and configuration. Usually you can create one connection pool per database proxy on Payara Server, just like we did in this article, and configure the proxy how it should dispatch requests for sessions. See links below for more information:
- https://pgdash.io/blog/pgbouncer-connection-pool.html
- https://github.com/CrunchyData/crunchy-proxy
- https://proxysql.com/
Payara Server Offers Flexible Database Access Configuration
As you can see, the Payara Server offers pretty high flexibility of database access configuration respecting your architecture. The right architectural decision is your decision - in general you have to think also on the opposite point of view from the database perspective - each runtime instance has it's own jdbc pool, so if you would have 100 server instances with only one pool with a maximum 100 connections all connecting to the same database server, in extreme the database server can see 100 x 100 incoming connections (and parallel statements).
Database servers usually have their own limits, queues, etc., so it may be very complicated to fine tune the whole system.
The Payara Platform is open source. Give it a try:
